用SHAP可视化解读数据特征的重要性:蜂巢图与特征关系图结合展示
用SHAP可视化解读数据特征的重要性:蜂巢图与特征关系图结合展示
在机器学习模型中,理解各个特征对预测结果的贡献度是一个重要且具有挑战性的问题。特别是在医疗等关键领域,模型的可解释性至关重要。本文将介绍如何使用SHAP(SHapley Additive exPlanations)值的可视化方法,结合蜂巢图与特征关系图,清晰展示模型中各特征的重要性。
背景
当构建一个机器学习模型时,通常会面临一个难题:如何解释各个特征在模型中的作用?这是一个非常重要的问题,特别是在医学等领域,理解模型的决策过程至关重要。在这篇文章中,将为揭示如何通过SHAP值的可视化,结合蜂巢图与特征关系图,帮助清晰地看到哪些特征在模型的预测中扮演了关键角色
在上图中,你看到的正是通过SHAP值分析心脏病预测模型的重要特征展示。每个点代表一个数据样本,颜色越红表明该特征原始值越高,越蓝则越低,你可以清晰地看到,例如“thal”和“ca”等特征在预测模型中具有较高的特征贡献度,它们直接影响模型的最终输出
接下来,将介绍如何通过代码组合shap可视化蜂巢图和特征贡献图,让复杂的机器学习模型变得更加透明和易于解释
代码实现
数据读取处理
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
plt.rcParams['font.family'] = 'Times New Roman'
plt.rcParams['axes.unicode_minus'] = False
import warnings
warnings.filterwarnings("ignore")
df = pd.read_csv('Dataset.csv')
# 划分特征和目标变量
X = df.drop(['target'], axis=1)
y = df['target']
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2,
random_state=42, stratify=df['target'])
df.head()
用于加载数据集、划分特征与目标变量,并将数据集按8:2的比例分为训练集和测试集,以便进行后续的机器学习模型训练和评估,此数据集为一个二分类数据集
模型构建
import xgboost as xgb
from sklearn.model_selection import GridSearchCV
# XGBoost模型参数
params_xgb = {
'learning_rate': 0.02, # 学习率,控制每一步的步长,用于防止过拟合。典型值范围:0.01 - 0.1
'booster': 'gbtree', # 提升方法,这里使用梯度提升树(Gradient Boosting Tree)
'objective': 'binary:logistic', # 损失函数,这里使用逻辑回归,用于二分类任务
'max_leaves': 127, # 每棵树的叶子节点数量,控制模型复杂度。较大值可以提高模型复杂度但可能导致过拟合
'verbosity': 1, # 控制 XGBoost 输出信息的详细程度,0表示无输出,1表示输出进度信息
'seed': 42, # 随机种子,用于重现模型的结果
'nthread': -1, # 并行运算的线程数量,-1表示使用所有可用的CPU核心
'colsample_bytree': 0.6, # 每棵树随机选择的特征比例,用于增加模型的泛化能力
'subsample': 0.7, # 每次迭代时随机选择的样本比例,用于增加模型的泛化能力
'eval_metric': 'logloss' # 评价指标,这里使用对数损失(logloss)
}
# 初始化XGBoost分类模型
model_xgb = xgb.XGBClassifier(**params_xgb)
# 定义参数网格,用于网格搜索
param_grid = {
'n_estimators': [100, 200, 300, 400, 500], # 树的数量
'max_depth': [3, 4, 5, 6, 7], # 树的深度
'learning_rate': [0.01, 0.02, 0.05, 0.1], # 学习率
}
# 使用GridSearchCV进行网格搜索和k折交叉验证
grid_search = GridSearchCV(
estimator=model_xgb,
param_grid=param_grid,
scoring='neg_log_loss', # 评价指标为负对数损失
cv=5, # 5折交叉验证
n_jobs=-1, # 并行计算
verbose=1 # 输出详细进度信息
)
# 训练模型
grid_search.fit(X_train, y_train)
# 使用最优参数训练模型
best_model = grid_search.best_estimator_
通过网格搜索找到最优的XGBoost模型参数,并训练最终模型,为后续SHAP值计算提供最佳的模型基础
shap值计算
import shap
explainer = shap.TreeExplainer(best_model)
# 计算shap值为numpy.array数组
shap_values_numpy = explainer.shap_values(X)
shap_values_numpy
针对训练好的XGBoost模型和完整的数据集计算SHAP值,以解释每个特征对模型预测的贡献
SHAP值特征贡献的蜂巢图
plt.figure()
shap.summary_plot(shap_values_numpy, X, feature_names=X.columns, plot_type="dot", show=False)
plt.savefig("SHAP_numpy summary_plot.pdf", format='pdf',bbox_inches='tight')
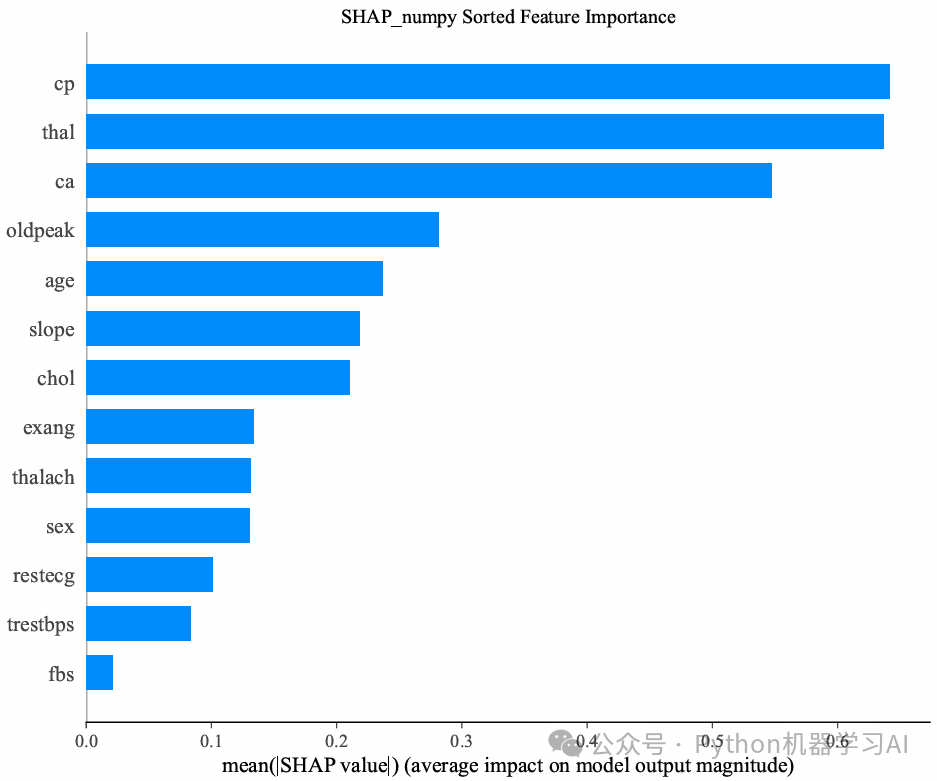
SHAP值排序的特征重要性柱状图
plt.figure(figsize=(10, 5), dpi=1200)
shap.summary_plot(shap_values_numpy, X, plot_type="bar", show=False)
plt.title('SHAP_numpy Sorted Feature Importance')
plt.tight_layout()
plt.savefig("SHAP_numpy Sorted Feature Importance.pdf", format='pdf',bbox_inches='tight')
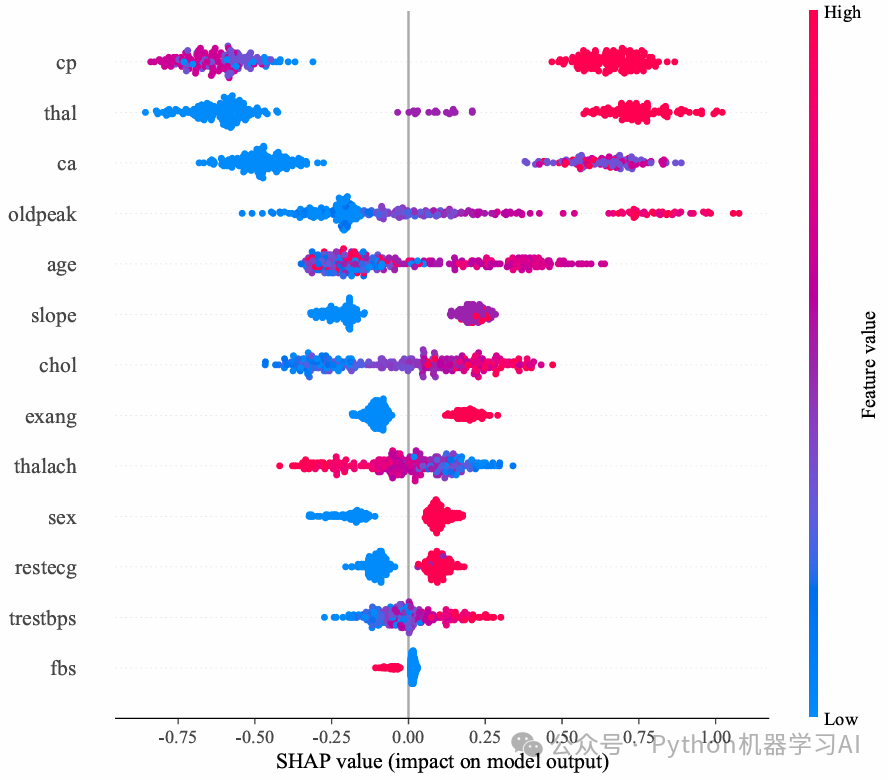
plt.show()
结合蜂巢图与特征重要性图的双轴SHAP可视化图
# 创建主图(用来画蜂巢图)
fig, ax1 = plt.subplots(figsize=(10, 8), dpi=1200)
# 在主图上绘制蜂巢图,并保留热度条
shap.summary_plot(shap_values_numpy, X, feature_names=X.columns, plot_type="dot", show=False, color_bar=True)
plt.gca().set_position([0.2, 0.2, 0.65, 0.65]) # 调整图表位置,留出右侧空间放热度条
# 获取共享的 y 轴
ax1 = plt.gca()
# 创建共享 y 轴的另一个图,绘制特征贡献图在顶部x轴
ax2 = ax1.twiny()
shap.summary_plot(shap_values_numpy, X, plot_type="bar", show=False)
plt.gca().set_position([0.2, 0.2, 0.65, 0.65]) # 调整图表位置,与蜂巢图对齐
# 在顶部 X 轴添加一条横线
ax2.axhline(y=13, color='gray', linestyle='-', linewidth=1) # 注意y值应该对应顶部
# 调整透明度
bars = ax2.patches # 获取所有的柱状图对象
for bar in bars:
bar.set_alpha(0.2) # 设置透明度
# 设置两个x轴的标签
ax1.set_xlabel('Shapley Value Contribution (Bee Swarm)', fontsize=12)
ax2.set_xlabel('Mean Shapley Value (Feature Importance)', fontsize=12)
# 移动顶部的 X 轴,避免与底部 X 轴重叠
ax2.xaxis.set_label_position('top') # 将标签移动到顶部
ax2.xaxis.tick_top() # 将刻度也移动到顶部
# 设置y轴标签
ax1.set_ylabel('Features', fontsize=12)
plt.tight_layout()
plt.savefig("SHAP_combined_with_top_line_corrected.pdf", format='pdf', bbox_inches='tight')
plt.show()
首先创建一个双轴图表,通过绘制SHAP值的蜂巢图和特征重要性柱状图,分别展示每个特征对模型预测的贡献及其平均特征重要性,蜂巢图在下方的X轴展示各特征的SHAP值分布,颜色代表特征值大小,而柱状图在上方的X轴展示每个特征的平均SHAP值作为重要性排序,代码调整了图表的位置以对齐蜂巢图与柱状图,并通过添加顶部X轴和横线来突出特征的平均贡献,最后将生成的双轴图保存为PDF文件