MySQL窗口函数实战:连续问题的两种解法
MySQL窗口函数实战:连续问题的两种解法
本文主要讲解了MySQL窗口函数在处理连续问题时的应用,通过三个具体的习题案例,详细介绍了两种主要解题方法:行号过滤法和错位比较法。文章内容深入浅出,既有理论讲解,又有具体代码实现,对于学习MySQL窗口函数的读者具有较高的参考价值。
一.做题技巧
对于连续问题有两种方法:行号过滤法,错位比较法
1.行号过滤法:主要通过排序类函数(rank,dense_rank,row_number),主用row_number生成新的一列行号,与区间进行差值运算,得到的临界结果,若相同,表示为连续同一连续区间
2.错位比较法:
法1:通过跨行类函数(lag,lead),生成与原数值错位N的值,进而解出问题
法2:通过row_number()或者row_number()+1分别生成原数据的错位的连续行号列,进行连表操作
二.习题一
代码准备
表格:
代码:
CREATE TABLE SQL_8
(
user_id varchar(2),
login_date date
);
INSERT INTO SQL_8 (user_id,login_date)
VALUES ('A', '2022-09-02'), ('A', '2022-09-03'), ('A', '2022-09-04'), ('B', '2021-11-25'),
('B', '2021-12-31'), ('C', '2022-01-01'), ('C', '2022-04-04'), ('C', '2022-09-03'),
('C', '2022-09-05'), ('C', '2022-09-04'), ('A', '2022-09-03'), ('D', '2022-10-20'),
('D', '2022-10-21'), ('A', '2022-10-03'), ('D', '2022-10-22'), ('D', '2022-10-23'),
('B', '2022-01-04'), ('B', '2022-01-05'), ('B', '2022-11-16'), ('B', '2022-11-17');
select * from SQL_8;
问题:找出这张表所有的连续3天登录用户
解法一:行号过滤法
连续N天登录用户,要求数据行满足以下条件:
解题思路:
1.userid要一样,表示同一用户
2.同一用户每行记录以登录时间从大到小进行排序
3.后一行记录要比前一行记录的登录时间多一天
4.数据行数大于等于N
思路:
1.利用row_number()创建一列排序列
2.创造出login_date与排序列相减的列,找三个或者三个以上的数相等,即为题目想要的用户
代码拆解:
第一步:去重
注释:这里去重的主要原因是,同一用户可能同一天登录多次(截图截取部分)
select distinct user_id, login_date from SQL_8;
第二步:利用row_number()将数据进行分组排列(截图截取部分)
with t1 as(
select distinct user_id, login_date from SQL_8)
select *, row_number() over (partition by user_id order by login_date) as rn from t1;
第三步:生成出login_date与rn的差值列
with t1 as (
select distinct user_id , login_date from SQL_8
),
t2 as (
select *,row_number() over (partition by user_id order by login_date)as rn from t1
)
select *, DATE_SUB(login_date,interval rn day)as sub from t2;
注释:这里指的是计算与login_date相差rn天,输出结果
DATE_SUB(date,interval value unit) date_add 是相加
date:这是一个必需的参数,表示要进行减法操作的起始日期或日期时间值。
value:同样是必需参数,代表要减去的时间间隔的数量,这个值必须是一个整数。
unit:也是必需参数,指定了时间间隔的单位。常见的单位包括 YEAR(年)、MONTH(月)、DAY(日)、HOUR(小时)、MINUTE(分钟)、SECOND(秒)等。
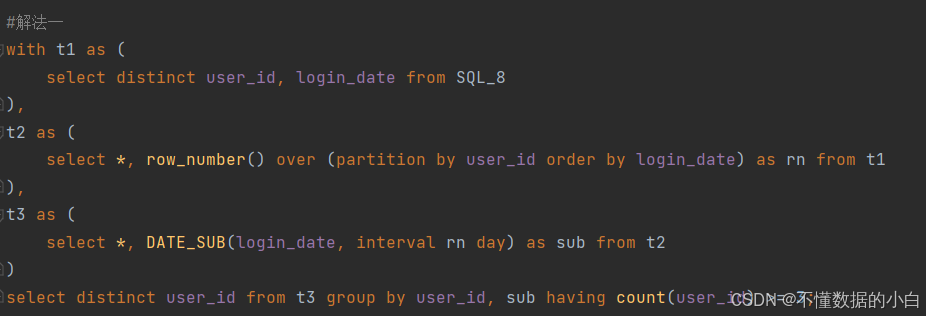
第四步:分组+去重+计数,筛选满足连续日期大于等于3的用户
注释:这里的去重主要是去除同一用户多次满足连续日期大于等于3
with t1 as (
select distinct user_id , login_date from SQL_8
),
t2 as (
select *,row_number() over (partition by user_id order by login_date)as rn from t1
),
t3 as (
select *, DATE_SUB(login_date,interval rn day)as sub from t2)
select distinct user_id from t3 group by user_id,sub having count(user_id)>=3;
解法二:错位比较法
原版bug版本
思路:
1.利用log(),滞后上一列得last_login_date
2.计算二者差值
3.计算同一用户,计数差值为1
代码拆解:
第一步:去重+生成滞后的一列的数
with t0 as(
select distinct user_id, login_date from SQL_8)
select *,lag(login_date,1) over (partition by user_id order by login_date asc)as last_login_date from t0;
第二步:利用datediff()函数对login_date和last_login_date进行计算差值并生成一列
with t0 as(
select distinct user_id, login_date from SQL_8),
t1 as (
select *,lag(login_date,1) over (partition by user_id order by login_date asc)as last_login_date from t0)
select *,datediff(login_date,last_login_date) as diff from t1;
第三步:
with t0 as(
select distinct user_id, login_date from SQL_8),
t1 as (
select *,lag(login_date,1) over (partition by user_id order by login_date asc)as last_login_date from t0),
t2 as(
select *,datediff(login_date,last_login_date) as diff from t1)
select distinct user_id from t2 where diff=1 group by user_id having count(user_id)>=2;
注释:这里错误的主要原因在于B用户,diff=1,会将其他不为1的筛选掉,留下可能不连续日期,进而影响数据结果
更正版(错位比较法)
思路:
1.利用lag(),滞后上一列得last_login_date,滞后上两列的last_two_login_date
2.计算二者差值,diff1和diff2
3.计算同一用户,满足计数差值为diff1=1&diff=2,即为满足的要求
更正,进行两次滞后,两次分别与原日期相减的diff1,diff2,若连续三天,则满足diff1=1,diff2=2
整体的代码:
with t0 as(
select distinct user_id, login_date from SQL_8),
t1 as(
select *,lag(login_date,1) over (partition by user_id order by login_date asc)as last_login_date,
lag(login_date,2) over (partition by user_id order by login_date asc) as last_two_login_date from t0),
t2 as(
select *,date diff(login_date,last_login_date)as diff1 , datediff(login_date,last_two_login_date) as diff2 from t1)
select distinct user_id from t2 where diff1=1 and diff2=2 group by user_id;
三:习题二
代码准备
表格:
代码:
CREATE TABLE SQL_9
(
player_id varchar(2),
score int,
score_time datetime
);
INSERT INTO SQL_9 (player_id, score, score_time)
VALUES ('B3', 1, '2022-09-20 19:00:14'), ('A2', 1, '2022-09-20 19:01:04'),
('A2', 3, '2022-09-20 19:01:16'), ('A2', 3, '2022-09-20 19:02:05'),
('A2', 2, '2022-09-20 19:02:25'), ('B3', 2, '2022-09-20 19:02:54'),
('A4', 3, '2022-09-20 19:03:10'), ('B1', 2, '2022-09-20 19:03:34'),
('B1', 2, '2022-09-20 19:03:58'), ('B1', 3, '2022-09-20 19:04:07'),
('A2', 1, '2022-09-20 19:04:19'), ('B3', 2, '2022-09-20 19:04:31'),
('A1', 2, '2022-09-20 19:04:51'), ('A1', 2, '2022-09-20 19:05:01'),
('B4', 2, '2022-09-20 19:05:06'), ('A1', 2, '2022-09-20 19:05:26'),
('A1', 2, '2022-09-20 19:05:48'), ('B4', 2, '2022-09-20 19:05:58');
问题:统计连续三次(及以上)为球队得分的球员名单
注释:该题和上一题的区别
上一题的连续指的是天,要想连续差值天数为1,而这题按照之前的思路,差值不能确定,但是连续三次即以上,即按照日期排序,连续出现三次的即为题目要求的球员名单
连续N次以上为球员得分,要求数据行满足以下条件:
解题思路:
1.player_id要一样,表示同一球员
2.每行记录以得分从小到大排序
3.对球员player_id进行滞后一次,滞后两次…..滞后N次,看球员id
4.判断N次滞后的player_id,是否都一样,若是即为题目要找的球员
解法:修正后(错位比较法)
代码拆解
第一步:生成滞后1次,滞后2次的列添加到后面
注意我犯得错误:加上了partition by player_id
错误原因:一旦加上partition by played_id就会对球员进行分组,这样必定会打乱时间的顺序,导致结果出错
select *,lag(player_id,1) over (order by score time )as lag_1
,lag(player_id,2) over (order by score time )as lag_2 from SQL_9;
第二步:筛选两次滞后值是非等于原player_id
with t1 as(
select *,lag(player_id,1) over (order by score time )as lag_1
,lag(player_id,2) over (order by score time )as lag_2 from SQL_9)
select distinct player_id from t1 where player_id= lag_1 and lag_1 =lag_2;
补充修正前的错误
代码:
with t1 as(
select *,lag(player_id,1) over (order by score time )as lag_1
from SQL_9)
select distinct player_id from t1 where player_id= lag_1
group by player_id having count(player_id)>=2;
注释:如图,红框的都满足A1=A1,但是中间有其他球员进球,group by后会直接将中间的数据剔除,进而合成一起,导致出错
四:习题三
代码准备
表格:
代码:
CREATE TABLE SQL_10
(
log_id int
);
INSERT INTO SQL_10 (log_id) VALUES (1), (2), (3), (7), (8), (10);
问题:编写SQL查询得到Logs表中的连续区间的开始数字和结束数字,按照start_id排序,查询结果如下
思路:
1.对原数据用row_number()进行排序
2.将新增原数据-排序数,差值添加到原表
3.对表进行分组,group by得出最大,最小
解法1(行号过滤法):
代码拆解:
第一步:对原数据用row_number(),新增一列排序列
select *,row_number() over(order by log_id) as mun from SQL_22;
第二步:将log_id与mun相减的值新增一列
with t1 as(
select * ,row_number() over(order by log_id) as mun from SQL_10)
select *,log_id-mun as rn from t1;
注释:第一步和第二步可以合并
select * ,log_id-row_number() over (order by log_id) as rn from SQL_10;
第三步:对用group by对rn进行分组,得出min(log_id)记作为start_id,max(log_id)记作为end_id
with t1 as(
select * ,row_number() over(order by log_id) as mun from SQL_10),
t2 as (
select * ,log_id-mun as rn from t1)
select min(log_id) as start_id, max(log_id) as end_id from t2 group by rn;
解法2(错位比较法):
略:解答方法二相对麻烦很多,就不在此演示了