RNN循环神经网络十问十答
RNN循环神经网络十问十答
循环神经网络(RNN)是深度学习领域中一种重要的神经网络模型,特别适用于处理序列数据。本文将从多个角度深入探讨RNN的相关知识,包括其历史背景、基本原理、特点、变种以及应用场景等。
1、RNN的作者及提出的年代
循环神经网络(RNN)的概念逐步发展而来的。早期对循环神经网络思想有贡献的包括 Sepp Hochreiter 等(也是LSTM的提出者)。1986 年,Rumelhart、Hinton 和 Williams 在他们的论文《Learning representations by back - propagation through time》中描述了通过时间反向传播(BPTT)来训练循环神经网络,这为 RNN 的有效训练提供了重要方法。
2、为什么叫循环神经网络?
可以从两个方面去理解“循环”:一是网络的正向传播过程中,有一个自循环的过程:
二是网络在反向传播时,有一个迭代的过程:
反向传播具体的公式推到详见RNN循环神经网络之原理讲解
3、为什么说RNN有记忆力?
根据如下公式可知:
在t时刻输出,依赖于t时刻的隐藏状态
,而
又依赖于
和
,以此类推。
中是含有前面输入数据的信息。所以RNN有一定的记忆能力。
4、为什么说RNN的记忆力又很短?
一是梯度消失与梯度爆炸的原因:梯度消失会使得较早时间步的信息在训练过程中难以有效地传递到当前时间步,模型难以学习到长期的依赖关系,就好像 “忘记” 了很久之前的信息。而梯度爆炸则会导致训练过程不稳定,参数更新过大,模型无法收敛,同样也影响了对长期信息的记忆和利用。
二是信息传递的方式:RNN 在每个时间步更新隐藏状态时,是将当前的输入和上一个时间步的隐藏状态进行线性组合,然后通过一个非线性激活函数得到新的隐藏状态。这种线性的信息传递方式在处理长序列时,信息的传递效率较低。随着序列长度的增加,较早时间步的信息在经过多次线性变换和非线性激活后,会逐渐被稀释,难以完整地保留和传递到后续时间步,导致模型对长序列中的早期信息记忆能力下降。
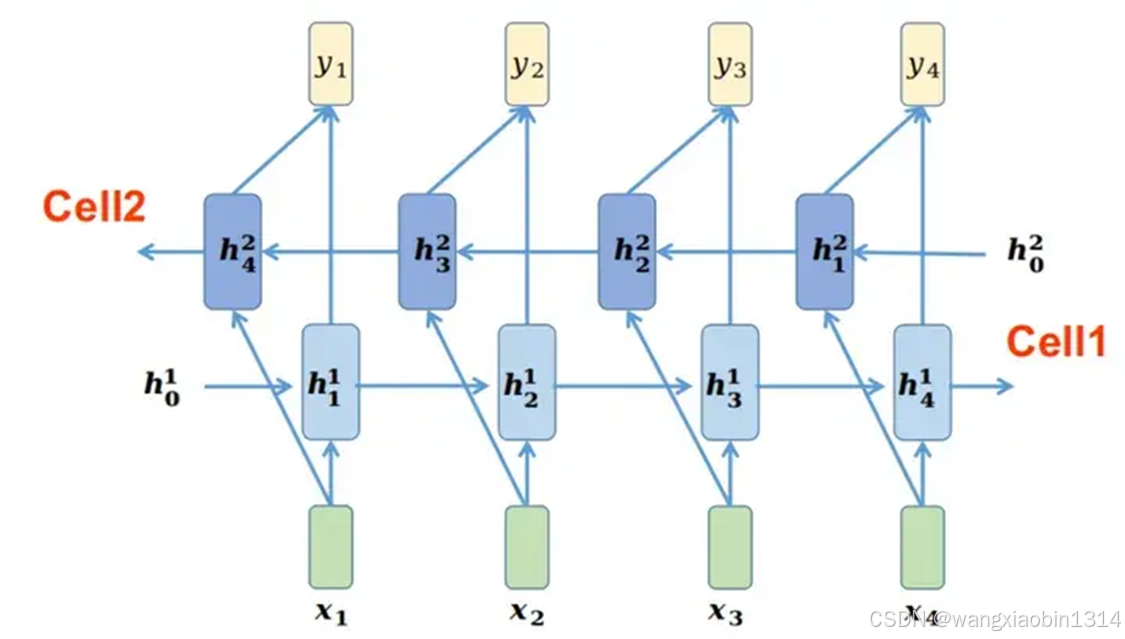
5、在RNN循环神经网络之原理讲解,其隐藏层是单层的,是否可以变成多层?
可以,就是多层循环神经网络,隐藏层有多层,具体架构如下图所示:
在每层的水平方向,只有一组可学习参数,如第l层的参数
,水平方向是数据沿着时间维度变换,变换机制与单个RNN的机制一致。在每个时刻t的垂直方向,共有L组可学习参数
i=1,2,...,L。在第l层的第t时刻cell的输入数据来自于2个方向,一个是来自水平方向t-1时刻的隐藏状态输入
,另一个是来自t时刻l-1层的隐藏状态输入
来自水平方向t-1时刻的隐藏状态:
来自t时刻l-1层的隐藏状态:
所以
6、如何理解双向循环神经网络?
当我们可以获得一条完整的输入序列时,即每个时刻的输入数据都可以同时获得。我们不仅可以利用RNN从左到右的进行计算,同时也可以从右到左进行计算。
表示t时刻,Cell1中从左到右获得的信息;
表示图中Cell1可学习参数;
表示Cell1的激活函数
表示t时刻,Cell2中从右到左获得的信息;
表示图中Cell2可学习参数;
表示Cell2的激活函数
- V是输出层的参数,可以理解为MLP
- 是输出层的激活函数
- 是t时刻的输出值
对于t时刻的输入,可以结合从左到右的
,获得当前时刻的
:
同理也可以结合从右到左的
,获得当前时刻的
:
然后将
和
首尾级联在一起通过输出网络V得到输出
:
这样对于任何一个时刻t可以看到从不同方向获得的信息,使得模型更容易优化,加速了模型的收敛速度。
7、既然rnn无法并行,是一个字一个字依次输入模型的,如何理解torch.rnn中batch?
回忆一下RNN的基本结构。RNN处理序列的时候,每个时间步依赖于前一个时间步的隐藏状态,所以时间步之间确实是串行的,无法并行。虽然时间步内部是串行的,但不同的样本之间是可以并行处理的。比如,一个批次里有多个样本,每个样本的序列处理虽然是按时间步进行的,但同一时间步内可以对不同样本同时进行计算。例如,在进行文本处理时,序列数据中包含了N条句子(这个N条句子之间相互独立,无先后顺序),一个 batch 可能包含了其中的若干条句子,样本间是可以并行计算的。
此外,batch主要是用于计算反向传播梯度的。如果不是按照batch输入,而是一个字一个字依次输入模型,计算梯度时采用的是随机梯度下降法,那么梯度的估计可能会非常不稳定,因为单个样本的特征可能具有较大的随机性。而使用一个 batch 的样本进行计算,可以对多个样本的梯度进行平均,从而得到更稳定、更准确的梯度估计,使得模型的训练更加稳定和收敛。
8、如何理解rnn的多对一 、一对多、多对多 等应用场景?请的分别举例说明?
在 RNN 的结构中,并不是每个时刻都要输出,根据任务需求的不同,我们可以自行决定,什么时候输出。比如我们在做情感分类任务时,一句话有多个文字,但只在最后时刻有个输出,表示 positive 或者 negtive。“多对一”的结构可以完成这个任务,如下图所示, 有多个输入,最后时刻的隐状态
,包含了整句话的信息,然后将
经过变换后输出这句话的情感状态。需要额外注意,下图只是一个结构示意图,图中蓝框不仅仅可以代表单个 RNN,有时候也可以代表 biRNN 模块或者 DeepRNN 模块。
顾名思义“One to Many”是只有一个时刻的输入,具有多个时刻输出的结构。如下图所示,比如我们要描绘一张图片的内容时,用一个 CNN 模型将图片映射为一个高维表示,记作
并作为 RNN 的输入,然后不断输出对图片的描述。
从 Encode 和 Decode 的架构看,“Many to Many”有两种不同的结构。一种是 Encode 和 Decode 分别用不同的模块,即参数不一样;另外一种是 Encode 和 Decode 共用同一个模块,即共用一组参数。如下图 是 Encode 和 Decode 不同模块的结构,常用于翻译任务中。这种结构可以看成是“Many to One”结构和“One to Many”结构的组合。
如下图是 Encode 和 Decode 属于相同模块的结构, 常用于“Language Modeling”
9、RNN目前的应用如何?
虽然transformer诞生后,被广泛使用,但RNN由于自身具备一定的优势,仍然被使用:
- 计算资源需求低:RNN 参数量相对较少,模型相对轻量化,在计算资源有限的环境,如一些边缘计算设备、移动设备上,RNN 可以在不占用过多资源的情况下运行,完成一些简单的序列处理任务。
- 处理特定序列数据有效:在处理一些具有强顺序依赖关系且序列长度相对较短的任务时,如简单的语音识别,RNN 能够较好地捕捉序列中的短期依赖信息,表现出不错的性能。
- 作为研究基础和对比基准:在学术研究中,RNN 常被用作基础模型或对比基准,帮助研究人员验证新算法、新架构的有效性,为新模型的开发提供参考和对比。
10、nn.RNN和nn.RNNCell的区别
- nn.RNN 可以处理整个序列,它会自动对序列中的每个时间步进行迭代计算,而 nn.RNNCell 只处理一个时间步。
- 使用 nn.RNN 时,你提供一个完整的序列作为输入,而使用 nn.RNNCell 时,你需要自己编写循环代码来处理序列中的每个时间步。
- 当你需要对 RNN 的每个时间步进行自定义操作时,例如添加额外的计算或条件判断,使用 nn.RNNCell 会更方便。
- 对于一些复杂的 RNN 架构,如 LSTM 或 GRU 的自定义实现,nn.RNNCell 是基础构建块。
通过使用 nn.RNNCell ,你可以灵活地构建自定义的循环神经网络,根据不同的需求调整循环逻辑,实现更具针对性的序列处理任务。