探索性数据分析(EDA)的数据可视化 | 附代码
创作时间:
作者:
@小白创作中心
探索性数据分析(EDA)的数据可视化 | 附代码
引用
CSDN
1.
https://blog.csdn.net/weixin_38739735/article/details/136639924
数据可视化是探索性数据分析的重要组成部分,它有助于分析和可视化数据,以获得对数据分布、变量之间的关系和潜在异常值的启示性见解。Python具有丰富的库,可以快速高效地创建可视化。
常用的数据可视化类型
在Python中,通常使用以下几种类型的可视化进行探索性数据分析:
- 柱状图:用于显示不同类别之间的比较。
- 折线图:用于显示随时间或不同类别的趋势。
- 饼图:用于显示不同类别的比例或百分比。
- 直方图:用于显示单个变量的分布。
- 热图:用于显示不同变量之间的相关性。
- 散点图:用于显示两个连续变量之间的关系。
- 箱线图:用于显示变量的分布并识别异常值。
使用Python创建数据可视化的步骤
- 理解业务问题:这是第一步,非常重要,因为我们将能够专注于获取正确的可视化。
- 导入必要的库:导入必要的库,例如Pandas、Seaborn、Matplotlib、Plotly等。
- 加载数据集:加载要可视化的数据集。
- 数据清理和预处理:清理和预处理数据,删除缺失值、重复值和异常值。此外,将分类数据转换为数值数据。
- 统计摘要:计算描述性统计量,例如均值、中位数、众数、标准差和相关系数,以了解变量之间的关系。
- 数据可视化与解释:创建可视化图表以了解数据的分布、关系和模式。之后解释可视化结果,从中获得关于数据的启示性见解和结论。
实战案例:心脏病数据集分析
1. 理解业务问题
心血管疾病是全球死亡的主要原因。根据世界卫生组织的数据,每年约有1,790万人死于心脏病。其中85%的死亡是由心脏病发作和中风引起的。在本文中,我们将探索来自Kaggle的心脏病数据集,并使用Python创建用于探索性数据分析的数据可视化。
2. 导入必要的库
# import libraries
import pandas as pd
import numpy as np
# data visualization
import matplotlib.pyplot as plt
import seaborn as sns
import plotly.express as px
import plotly.graph_objects as go
from plotly.subplots import make_subplots
3. 加载数据集
让我们将数据加载到一个Pandas DataFrame中,并开始探索它。
heart = pd.read_csv('heart.csv')
4. 数据清理和预处理
数据清理的目的是准备好我们的数据进行分析和可视化。
# 检查是否存在任何空值
heart.isnull().sum().sort_values(ascending=False).head(11)
# 检查重复值
heart.duplicated().sum()
# 删除重复值
heart.drop_duplicates(keep='first', inplace=True)
5. 统计摘要
# 获取数据集的统计摘要
heart.describe().T
6. 数据可视化与解释
基于性别的数据可视化
# Compare Heart Attack vs Sex
df = pd.crosstab(heart['output'],heart['sex'])
sns.set_style("white")
df.plot(kind="bar",
figsize=(6,6),
color=['#c64343', '#e1d3c1']);
plt.title("Heart Attack Risk vs Sex ", fontsize=16)
plt.xlabel("0 = Lower Risk 1 = Higher Risk", fontsize=16)
plt.ylabel("Amount", fontsize=16)
plt.legend(["Female","Male"], fontsize=14)
plt.xticks(rotation=0)
解释:男性患心脏病的风险更高。
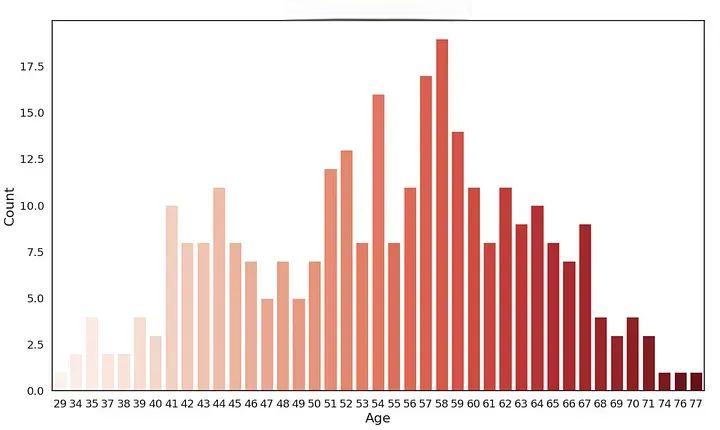
基于年龄的数据可视化
plt.figure(figsize=(14,8))
sns.set(font_scale=1.2)
sns.set_style("white")
sns.countplot(x=heart["age"],
palette='Reds')
plt.title("Count of Patients Age",fontsize=20)
plt.xlabel("Age",fontsize=16)
plt.ylabel("Count",fontsize=16)
plt.show()
解释:大多数患者的年龄在50-60岁之间。其中,患者中年龄为58岁的人数最多。
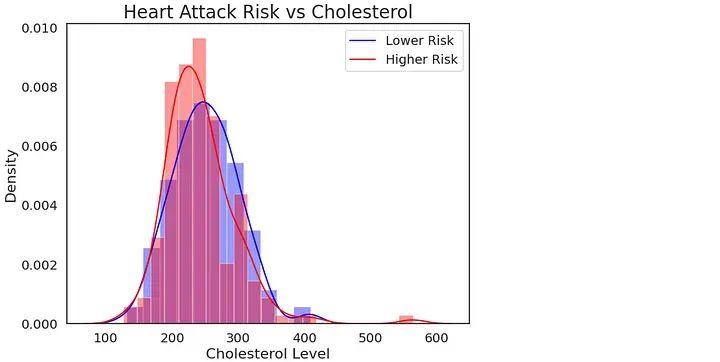
基于胆固醇水平的数据可视化
# Attack vs Cholesterol analysis
sns.set(font_scale=1.3)
plt.figure(figsize=(8,6))
sns.set_style("white")
sns.distplot(heart[heart["output"]==0]["chol"],
color="blue")
sns.distplot(heart[heart["output"]==1]["chol"],
color="red")
plt.title("Heart Attack Risk vs Cholesterol", size=20)
plt.xlabel("Cholesterol Level", fontsize=16)
plt.ylabel("Density", fontsize=16)
plt.legend(["Lower Risk","Higher Risk"], fontsize=14)
plt.show()
解释:
- 大多数患者的胆固醇水平在200-300之间。
- 随着年龄的增长,体内胆固醇水平增加的可能性很高。
基于胸痛类型的数据可视化
# 心脏病发作与胸痛类型的关系
df = pd.crosstab(heart3['cp'], heart['output'])
# 使交叉表更加直观
sns.set(font_scale=1.3)
sns.set_style("white")
df.plot(kind='bar',
figsize=(11,7),
color=['#e1d3c1', '#c64343']);
plt.title("心脏病发作风险与胸痛类型的关系", fontsize=20)
plt.xlabel("胸痛类型", fontsize=16)
plt.ylabel("数量", fontsize=16)
plt.legend(['低风险','高风险'], fontsize=14)
plt.xticks(rotation=0);
解释:
- 大多数患者属于典型心绞痛类型。
- 非心绞痛患者患心脏病的风险更高。
基于相关性的数据可视化
plt.figure(figsize=(12,10))
sns.set(font_scale=0.9)
sns.heatmap(heart.corr(),
annot=True,
cmap='Reds')
plt.title("变量间的相关性", size=15)
plt.show()
解释:
热图显示了以下变量之间的相关性:
- 胸痛类型(cp)和输出
- 达到的最大心率(thalachh)和输出
- 斜率(sp)和输出
我们还可以看到以下变量之间存在较弱的相关性:
- oldpeak:之前的峰值和输出
- caa:主要血管数量和输出
- exng:运动诱发性心绞痛
结论
在本文中,我们使用数据可视化来检查我们的数据集,创建了多个图表,如条形图、饼图、线图、直方图、热图。探索性数据分析(EDA)和数据可视化的主要目的是在做出任何假设之前帮助理解数据。它们帮助我们查看分布、摘要统计信息、变量之间的关系和异常值。
热门推荐
DIY家具必备:一文读懂木工胶水选购指南
智能聚合技术:环保木工胶的未来
永固化工教你如何挑选耐用又环保的木工胶水?
白乳胶:家居装修的环保粘合剂
北京夜景摄影指南:拍出最美月亮
讲好民心相通新故事 2025丝路春晚传播量创新高
4种在PPT中实现视觉吸引力强布局设计的方法
低血糖昏迷抢救六步法是什么
低血糖怎么恢复正常
庆阳美食大挑战:你敢尝试吗?
周祖陵景区:三千年文化传承的生态公园
庆阳必打卡:周祖陵景区上榜热门景点
庆阳冬日打卡:古镇年味、玻璃桥观景与冰挂美景
九皇山:绵阳最美自然景观打卡地
牙齿缺失不仅影响发音,还会带来这些困扰!
退役军人持优待证可以免费乘坐地铁吗?走绿色通道进出站吗?
维尼修斯错失金球,皇马全队拒绝出席,是输不起还是真的有阴谋?
南宋御街,走寻南宋历史
冬日打卡:天台山华顶森林公园赏雪攻略
天台华顶山的云锦杜鹃林,美到爆表!
孙中山与中山市:一段名字背后的传奇
孙中山诞辰纪念:中山市的由来揭秘
东北八大特色名菜推荐,每一道都凝聚着黑土地的风味与情怀
初五【慧•健康】远离假期高血糖
低血糖怎么治疗才不会复发
预防心肌炎,从抵御COVID-19开始
心肌炎患者的饮食调理全攻略
理性情绪疗法:解决牙齿缺失的心理困扰
老人缺牙后如何吃出健康?
平江路:听评弹品江南,邂逅最地道的苏式生活