HiveSQL分区的作用及创建分区表案例演示(图解)
创作时间:
作者:
@小白创作中心
HiveSQL分区的作用及创建分区表案例演示(图解)
引用
CSDN
1.
https://blog.csdn.net/2501_90330685/article/details/145250928
HiveSQL分区是大数据处理中一个重要的概念,它可以帮助我们更高效地管理和查询大规模数据集。本文将详细介绍HiveSQL分区的作用,以及如何创建和使用单级分区表和多级分区表。通过具体的SQL语句和案例演示,帮助读者深入理解HiveSQL分区的原理和实践。
一、分区的作用
HiveSQL分区的作用是将数据划分为更小的部分,以及根据特定的字段值将数据进行组织和管理。分区的原理是通过在数据存储和查询过程中利用分区信息来提高性能和查询效率,避免全表扫描,通俗来讲分区相当于分文件夹。
具体来说,HiveSQL分区的作用包括以下几个方面:
数据组织和管理:分区可以将数据按照特定的字段值进行组织和管理。通过将数据划分为更小的分区,可以更方便地进行数据的存储、查询和维护。
查询性能优化:分区可以根据查询的条件过滤掉不满足条件的分区,从而减少需要扫描的数据量,提高查询的性能和效率。尤其是对于大规模数据集的查询,在使用分区时可以显著减少查询的时间。
并行处理能力提升:分区可以将数据划分为更小的单元,从而提供更好的并行处理能力。在查询时,可以同时处理不同的分区,从而提高查询的并发性和整体的查询性能。
存储空间优化:对于分区表,可以根据不同分区的特点选择不同的存储策略。例如,对于不经常查询的历史数据可以选择压缩存储,从而减少存储空间的占用。
数据分析和统计:通过分区,可以更方便地进行数据分析和统计工作。例如,可以根据不同分区的数据分布情况,对不同分区的数据进行分析和处理,从而得到更精确的结果。
总的来说,HiveSQL分区的作用是提供更好的数据组织、查询性能优化、并行处理能力、存储空间优化以及数据分析和统计的功能,从而更高效地管理和查询大规模数据集。
二、单级分区表
1. 准备工作
-- 创建数据库
create database if not exists game;
-- 切库
use game;
2. 创建数据表
-- 1. 建表.
create table t_all_hero(
id int comment 'ID',
name string comment '英雄',
hp_max int comment '最大生命',
mp_max int comment '最大法力',
attack_max int comment '最高物攻',
defense_max int comment '最大物防',
attack_range string comment '攻击范围',
role_main string comment '主要定位',
role_assist string comment '次要定位'
) comment '射手表'
row format delimited fields terminated by '\t';
3. 查询数据
select * from t_all_hero;
3.1 查询出所有的archer数据
select * from t_all_hero where role_main='archer';
*问:虽然我们实现了需求, 但是需要进行全表扫描, 如何精准的获取到我们想要的数据呢?*
*答:可以采用分区表的思路来管理, 把各个职业的数据放到不同的文件夹中即可*
4. 创建分区数据表
-- 1. 创建分区表, 指定分区字段.
create table t_all_hero_part(
id int comment 'ID',
name string comment '英雄',
hp_max int comment '最大生命',
mp_max int comment '最大法力',
attack_max int comment '最高物攻',
defense_max int comment '最大物防',
attack_range string comment '攻击范围',
role_main string comment '主要定位',
role_assist string comment '次要定位'
) comment '角色表'
partitioned by (role string comment '角色字段-充当分区字段') -- 核心细节: 分区字段必须是表中没有的字段.
row format delimited fields terminated by '\t';
*注意:分区字段必须是新的字段,表中没有的字段哦*
5. 添加数据
5.1 添加方式1:静态分区(需要指定分区字段和值)
load data local inpath '/export/hivedata/archer.txt' into table t_all_hero_part partition(role='sheshou');
load data local inpath '/export/hivedata/assassin.txt' into table t_all_hero_part partition(role='cike');
load data local inpath '/export/hivedata/mage.txt' into table t_all_hero_part partition(role='fashi');
load data local inpath '/export/hivedata/support.txt' into table t_all_hero_part partition(role='fuzhu');
load data local inpath '/export/hivedata/tank.txt' into table t_all_hero_part partition(role='tanke');
load data local inpath '/export/hivedata/warrior.txt' into table t_all_hero_part partition(role='zhanshi');
5.1.1 此时HDFS中已已经根据我们的要求分好区
5.1.2 我们再次查询archer所有的数据时就可以根据分区字段进行筛选,避免全表扫描,提高查询效率.
select * from t_all_hero_part where role='sheshou';
5.2 添加方式2:动态分区(只需指定分区字段,分区字段相同的数据自动分配到同一个区)
*在进行动态分区前建议: 手动关闭严格模式*
set hive.exec.dynamic.partition.mode=nonstrict;
5.2.1 创建分区表
-- 1. 创建分区表.
create table t_all_hero_part_dynamic(
id int comment 'ID',
name string comment '英雄',
hp_max int comment '最大生命',
mp_max int comment '最大法力',
attack_max int comment '最高物攻',
defense_max int comment '最大物防',
attack_range string comment '攻击范围',
role_main string comment '主要定位',
role_assist string comment '次要定位'
) comment '角色表'
partitioned by (role string comment '角色字段-充当分区字段') -- 核心细节: 分区字段必须是表中没有的字段.
row format delimited fields terminated by '\t';
5.2.2 动态分区方式添加数据
*由于建表时增加一个role的分区字段,所以总共有9个普通字段和1个分区字段,所以插入数据时select语句中需要单独加上一个分区字段*
-- 2. 动态分区的方式, 添加数据.
insert into table t_all_hero_part_dynamic partition(role)
select *, role_main from t_all_hero; -- role main字段做为分区字段使用
5.2.3 查询分区表所有数据
-- 3. 查询分区表的数据.
select * from t_all_hero_part_dynamic;
5.2.4 查询分区表中archer所有数据
select * from t_all_hero_part_dynamic where role='archer';
三、多级分区表
*我们已经了解了单级分区但实际开发中在数据量比较大的情况下大多数采用多级分区来存储数据, 多级分区一般用采用时间来分区, 可以是: 年, 月, 日...。分区层级不建议超过3级, 一般是: 年, 月2级就够了。*
1. 准备工作
-- 创建数据库
create database if not exists products;
-- 切库
use products;
2. 创建分区表(按照年、月分区)
-- 1. 创建商品表, 按照: 年, 月分区.
create table products(
pid int,
pname string,
price int,
cid string
) comment '商品表'
partitioned by (year int, month int) -- 按照年, 月分区, 2级分区
row format delimited fields terminated by ',';
3. 查询数据
3.1 查找2023年1月分区下的所有数据
-- 查找2023年1月分区下的所有数据
select * from products where year=2023 and month=1;
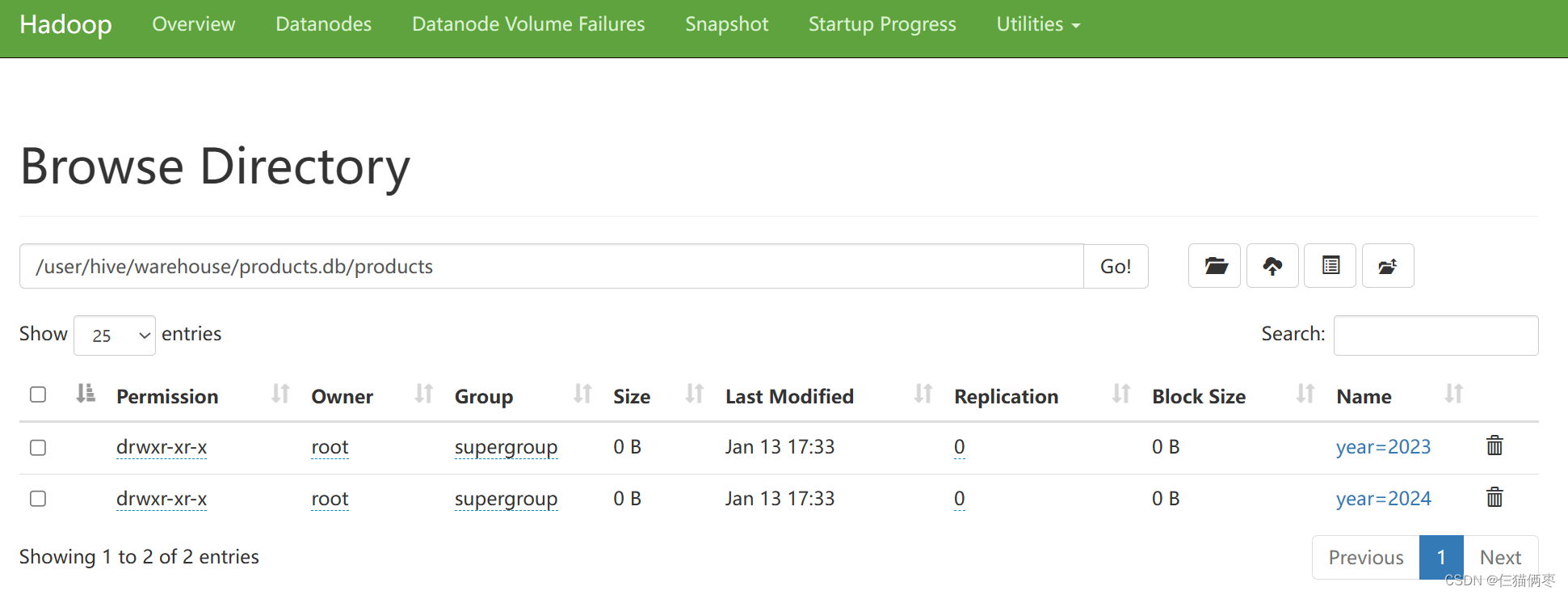
3.1.2 HDFS中已经按要求分为2023年和2024年两个区,并且也分了二级月分区
4. 修改分区
4.1 把2023年1月修改为 2023年5月
-- 2. 修改分区. 例如: 把2023年1月修改为 2023年5月
热门推荐
如何判断番茄是否成熟?识别成熟番茄的技巧是什么?
北回归线:穿越16个国家的神秘纬线
王者荣耀:如何根据英雄定位与个人风格,打造最强阵容?
Spring框架中的AOP是什么? Spring AOP的定义与应用场景
临床试验中异常值的临床意义判断标准
如何锻炼腿部肌肉
Hyrox训练计划分享:每周4-5次的极限运动训练指南
孩子手蜕皮,家长需要知道这些!
执行异议申请书样板:法律实务操作指南与规范解析
孩子同时出现头痛和心脏疼的原因是什么
却将万字平戎策,换得东家种树书。
“却将万字平戎策,换得东家种树书。”辛弃疾《鹧鸪天》全词翻译赏析
为什么现代人都不再相信八字命理?
高考390分左右可以上什么大学?多省汇总(2025参考)
理解“兆”单位的多重含义及其在生活中的实际应用
探索“兆”的含义:科技、经济与文化中的重要数字单位解析
香港审计公司收费:了解费用结构及如何选择合适的服务商
香港公司年审及做账审计费用详解:透明化流程与费用解析
大学生校园贷的原因及应对策略分析
法律职业资格考试专科生可以考吗
销售管理简历如何优化
手部全面麻木应如何进行检查
手部神经损伤怎么办?神经损伤手麻木的康复治疗:神经修复技术助力功能恢复
教育心理学知识的获得
运动后恢复身体能量的七大科学建议
物业管理费收滞纳金是否合法
宽仁·节日说健康丨春节狂欢的背后,这些醉酒处理方法和常见误区你一定要知道!
竹炭生产工艺详解
如何查看电脑显卡是否已开启 显卡激活方案
品牌的市场定位是什么?有哪些特征?