使用LSTM进行股票价格的时间序列预测
创作时间:
作者:
@小白创作中心
使用LSTM进行股票价格的时间序列预测
引用
CSDN
1.
https://m.blog.csdn.net/weixin_43729592/article/details/145108331
本文将详细介绍如何使用LSTM(长短期记忆网络)进行股票价格的时间序列预测。通过Python代码实现数据加载、预处理、模型定义、训练和结果可视化等多个步骤,帮助读者理解LSTM模型在实际问题中的应用。
1. 导入库并加载数据
import torch
import torch.nn as nn
import pandas as pd
import numpy as np
from sklearn.preprocessing import MinMaxScaler
from sklearn.model_selection import train_test_split
from torch.utils.data import DataLoader, Dataset
from torch.utils.data import TensorDataset
import matplotlib.pyplot as plt
from tqdm import tqdm # 导入tqdm库
import warnings # 避免一些可以忽略的报错
warnings.filterwarnings('ignore') # 过滤警告信息
plt.rcParams['font.sans-serif'] = ['SimHei'] # 正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False # 正常显示负号
# 加载数据
df = pd.read_csv("Microsoft_Stock.csv")
print(f"len(df): {len(df)}")
df.head()
# 提取收盘价数据
Close = df['Close'].values
print(f"Close: {len(Close)}") # Close:1511
# 绘制收盘价变化图
plt.plot([i for i in range(len(Close))], Close)
- 导入必要的库,包括 PyTorch、Pandas、Numpy、sklearn、Matplotlib 等。
- 读取 CSV 文件,提取相关列(如 Date、Open、High、Low、Close),并绘制收盘价变化图。
2. 数据预处理与归一化
# 选择相关的列,数据列名为:['Date', 'Open', 'High', 'Low', 'Close']
df = df[['Date', 'Open', 'High', 'Low', 'Close']]
# 转换日期为日期类型
df['Date'] = pd.to_datetime(df['Date'])
# 使用 MinMaxScaler 归一化数据
scaler = MinMaxScaler(feature_range=(-1, 1))
scaled_data = scaler.fit_transform(df[['Open', 'High', 'Low', 'Close']])
# 设置时间窗口 (Sequence Length)
seq_length = 3 # 过去3天的数据来预测当天的收盘价
# 数据划分函数
def split_data(data, seq_length):
dataX = []
datay = []
for i in range(len(data)-seq_length):
dataX.append(data[i:i+seq_length])
datay.append(data[i+seq_length, 3]) # 收盘价是目标数据(归一化后对应第4列)
dataX = np.array(dataX).reshape(len(dataX), seq_length, -1)
datay = np.array(datay).reshape(len(dataX), -1)
return np.array(dataX), np.array(datay)
# 创建数据集
dataX, datay = split_data(scaled_data, seq_length)
print(f"dataX.shape: {dataX.shape}, datay.shape: {datay.shape}")
- 选择需要的列并将日期列转换为日期类型。
- 使用 MinMaxScaler 对数据进行归一化,范围为 [-1, 1]。
- 设置时间窗口为 3,表示使用过去 3 天的数据来预测当天的收盘价。
- 使用 split_data 函数将数据划分为输入序列(dataX)和目标序列(datay)。
3. 训练集和测试集划分
# 数据集划分
X_train, X_test, y_train, y_test = train_test_split(dataX, datay, test_size=0.2, shuffle=False)
print(f"X_train.shape: {X_train.shape}, X_test.shape: {X_test.shape}")
# 转换为 PyTorch 张量
X_train = torch.tensor(X_train, dtype=torch.float32)
Y_train = torch.tensor(y_train, dtype=torch.float32)
X_test = torch.tensor(X_test, dtype=torch.float32)
Y_test = torch.tensor(y_test, dtype=torch.float32)
# 打印训练集输入张量的形状
print('X_train: ', X_train.shape)
print('Y_train: ', Y_train.shape)
# 创建训练数据集和加载器
train_dataset = TensorDataset(X_train, Y_train)
train_loader = DataLoader(train_dataset, batch_size=32, shuffle=False)
# 创建测试数据集和加载器
test_dataset = TensorDataset(X_test, Y_test)
test_loader = DataLoader(test_dataset, batch_size=32, shuffle=False)
- 使用 train_test_split 将数据集拆分为训练集和测试集。
- 将 NumPy 数组转换为 PyTorch 张量。
- 使用 TensorDataset 和 DataLoader 创建训练集和测试集的加载器。
4. 定义 LSTM 模型
# LSTM 模型定义
class LSTMModel(nn.Module):
def __init__(self, input_size=4, hidden_size=64, output_size=1, num_layers=3):
super(LSTMModel, self).__init__()
self.hidden_size = hidden_size
self.num_layers = num_layers
self.lstm = nn.LSTM(input_size, hidden_size, num_layers, batch_first=True)
self.fc = nn.Linear(hidden_size, output_size)
def forward(self, x):
h0 = torch.zeros(self.num_layers, x.size(0), self.hidden_size) # 初始化隐藏状态h0
c0 = torch.zeros(self.num_layers, x.size(0), self.hidden_size) # 初始化记忆状态c0
out, _ = self.lstm(x, (h0, c0)) # 仅返回最后一个时间步的输出
out = self.fc(out[:, -1, :]) # 取最后一个时间步的输出
return out
# 初始化模型
model = LSTMModel(input_size=4, hidden_size=64, output_size=1, num_layers=1)
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model.to(device)
- 定义 LSTM 模型类,继承自 nn.Module。
- 在 init 中初始化 LSTM 层和全连接层。
- 在 forward 方法中定义前向传播过程。
- 初始化模型,并将模型移动到 GPU(如果可用)。
5. 训练模型
# 训练模型
criterion = nn.MSELoss() # 使用均方误差损失函数
optimizer = torch.optim.Adam(model.parameters(), lr=0.001)
epochs = 100 # 设置训练轮数
train_losses = []
val_losses = []
for epoch in range(epochs):
model.train()
running_train_loss = 0.0
for x_train, y_train in tqdm(train_loader, desc=f"Epoch {epoch+1}/{epochs} - Training", ncols=100):
x_train, y_train = x_train.to(device), y_train.to(device)
optimizer.zero_grad() # 清空梯度
y_train_pred = model(x_train) # 模型预测
loss = criterion(y_train_pred, y_train) # 计算损失
loss.backward() # 反向传播
optimizer.step() # 更新权重
running_train_loss += loss.item() * x_train.size(0) # 累加训练损失
epoch_train_loss = running_train_loss / len(train_loader.dataset)
train_losses.append(epoch_train_loss)
# 验证集评估
model.eval()
running_val_loss = 0.0
with torch.no_grad():
for x_test, y_test in test_loader:
x_test, y_test = x_test.to(device), y_test.to(device)
y_test_pred = model(x_test) # 模型预测
loss = criterion(y_test_pred, y_test) # 计算损失
running_val_loss += loss.item() * x_test.size(0) # 累加验证损失
epoch_val_loss = running_val_loss / len(test_loader.dataset)
val_losses.append(epoch_val_loss)
print(f"Epoch {epoch+1}/{epochs}, Train Loss: {epoch_train_loss:.4f}, Validation Loss: {epoch_val_loss:.4f}")
- 设置损失函数为均方误差 (MSELoss),优化器为 Adam。
- 在每个 epoch 中训练模型,并记录训练损失和验证损失。
- 使用 tqdm 显示训练进度条。
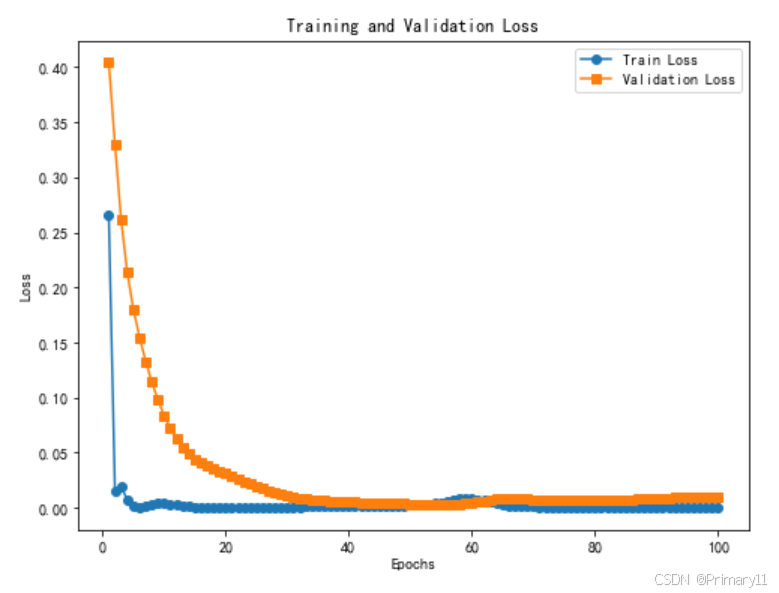
6. 绘制损失曲线和预测结果
# 绘制训练和验证损失曲线
plt.figure(figsize=(8, 6))
plt.plot(range(1, epochs+1), train_losses, label='Train Loss', marker='o')
plt.plot(range(1, epochs+1), val_losses, label='Validation Loss', marker='s')
plt.xlabel('Epochs')
plt.ylabel('Loss')
plt.title('Training and Validation Loss')
plt.legend()
# 获取模型预测值并反归一化
predictions = model(X_test).detach().numpy().reshape(-1, 1)
real_values = Y_test.detach().numpy().reshape(-1, 1)
# 将 predictions 和 real_values 转换为 (302, 4) 的数组,填充前三列为零
predictions = np
.column_stack([np.zeros((predictions.shape[0], 3)), predictions]) # 填充前三列为零
real_values = np.column_stack([np.zeros((real_values.shape[0], 3)), real_values]) # 填充前三列为零
# 反归一化
predictions = scaler.inverse_transform(predictions)[:, 3] # 提取最后一列(即收盘价)
real_values = scaler.inverse_transform(real_values)[:, 3] # 提取最后一列(即收盘价)
# 绘制预测结果与真实值
plt.figure(figsize=(12, 6))
plt.plot(real_values, label='真实值', color='blue')
plt.plot(predictions, label='预测值', color='red', linestyle='dashed')
plt.xlabel('时间步')
plt.ylabel('股票价格')
plt.title('LSTM 模型预测结果 vs 真实值')
plt.legend()
plt.show()
- 绘制训练损失和验证损失的曲线。
- 对模型的预测结果进行反归一化处理,确保恢复到原始的股票价格范围。
- 绘制真实值与预测值的对比图。
热门推荐
场景记忆法,特别适合职场人!
民间说的几厘利息是百分之几?
乏燃料再利用经济效益
提升车动力的方法有哪些?这些方法的效果如何评估?
怎样洗车才能有效保护车漆?保护车漆的洗车方法有哪些注意事项?
AI多实例分割技术的应用篇
如果学校有校企合作公司,学生能自主实习吗
公司总资产是什么构成?了解公司总资产对企业分析有何意义?
文艺复兴的实质是什么?文艺复兴的核心思想
七龙珠"角色深度解析:悟空与贝吉塔的实力较量
无锡自驾去成都:合理中途休息点、路线规划、所需时间及沿途景点一览
如何进行资产多元化投资
个税App全面解析:全年一次性奖金收入税务处理
男性增强CT后多久可以备孕
普洱茶与普通茶叶的区别及全面解析:从制作工艺到品鉴方法
幽门螺杆菌根除与胃癌防控有关吗
每天1个鸡蛋早晚吃出事?10个关于吃鸡蛋的问题,建议都搞搞清楚。
深蓝汽车连续两年销量未及预期,邓承浩2025年50万辆目标恐难实现
树脂补牙当天能刷牙吗?附上几个补牙后需要注意的事项快收藏!
市场分析方法有哪些?
带草字头寓意好的字女孩
棚户区改造助力城市更新与居民幸福生活
鬼灭之刃:半天狗七上月四形态综合指南
高性能富锂锰基正极材料改性研究
如何集成化管理API,方便企业内外部调用?
最大摄氧量和跑力指数揭示你的跑步潜力
计算机类就业率高的专业有哪些?
旅行摄影必备:揭晓最佳万能镜头推荐清单
购房合同审查要点及违约金规定详解
美联储如何在利率走廊内调整联邦基金利率?