MySQL rand()函数、rand(n)、生成不重复随机数
MySQL rand()函数、rand(n)、生成不重复随机数
MySQL提供了rand()函数来生成随机数,这对于数据库开发者来说是一个非常有用的工具。本文将详细介绍rand()函数的基本使用方法,以及它与其他函数的组合使用方式。
一、rand()与rand(n)
rand():无参数的rand()函数会生成一个[0,1)之间的float型随机数。每次生成的随机数都是随机的,不可重复的。
rand(n):有参数的rand(n)函数使用参数n作为随机数生成的种子。每次使用相同的种子值n,将得到相同的随机排序结果。这种随机数是可重复的,也是伪随机的。
需要注意的是,频繁地在一个很大的数据集上使用RAND()可能会导致性能问题,因为这会导致数据库引擎在每次查询时都生成一个新的随机数。
示例如下:
mysql> select rand(),rand(),rand();
+--------------------+--------------------+-------------------+
| rand() | rand() | rand() |
+--------------------+--------------------+-------------------+
| 0.9601070507989331 | 0.7956807881553478 | 0.098082819113585 |
+--------------------+--------------------+-------------------+
1 row in set (0.00 sec)
mysql> select rand(1),rand(1),rand(1);
+---------------------+---------------------+---------------------+
| rand(1) | rand(1) | rand(1) |
+---------------------+---------------------+---------------------+
| 0.40540353712197724 | 0.40540353712197724 | 0.40540353712197724 |
+---------------------+---------------------+---------------------+
1 row in set (0.00 sec)
我们发现:
- 当直接调用rand()函数时,每次生成的随机数都是不同的。
- 当直接调用rand(n)函数时,若种子n相同,则生成的随机数是可重复且多次查询是一致的。
为了便于理解上面两种示例,我们把rand(),rand(n) 结合表数据一起看一下。
mysql> CREATE TABLE t (i INT);
Query OK, 0 rows affected (0.42 sec)
mysql> INSERT INTO t VALUES(1),(2),(3);
Query OK, 3 rows affected (0.00 sec)
Records: 3 Duplicates: 0 Warnings: 0
-- 如下:rand()函数查询了两次,每次查询每一行返回的随机数都不相同
mysql> SELECT i, RAND() FROM t;
+------+------------------+
| i | RAND() |
+------+------------------+
| 1 | 0.61914388706828 |
| 2 | 0.93845168309142 |
| 3 | 0.83482678498591 |
+------+------------------+
3 rows in set (0.00 sec)
mysql> SELECT i, RAND() FROM t;
+------+------------------+
| i | RAND() |
+------+------------------+
| 1 | 0.35877890638893 |
| 2 | 0.28941420772058 |
| 3 | 0.37073435016976 |
+------+------------------+
3 rows in set (0.00 sec)
-- 如下:rand(n)函数查询了两次
-- 同一次查询中可能会返回重复的数字(注意:数据量小的情况不一定有重复值)
-- 但是多次查询时,第二次与第一次返回的结果相同。
mysql> SELECT i, RAND(3) FROM t;
+------+------------------+
| i | RAND(3) |
+------+------------------+
| 1 | 0.90576975597606 |
| 2 | 0.37307905813035 |
| 3 | 0.90576975597606 |
+------+------------------+
3 rows in set (0.00 sec)
mysql> SELECT i, RAND(3) FROM t;
+------+------------------+
| i | RAND(3) |
+------+------------------+
| 1 | 0.90576975597606 |
| 2 | 0.37307905813035 |
| 3 | 0.90576975597606 |
+------+------------------+
3 rows in set (0.01 sec)
可以发现:
- rand()函数:每次查询都生成不一样的数据。同一次查询中每行数据的随机数都不一样;多次查询时与上一次生成的随机数也不一致。
- rand(n)函数:同一次查询中数据可能会产生重复(注意:数据量小的情况不一定有重复值);多次查询时与上一次生成的随机数是一致的。即是指定了随机数的种子,那么多次查询的结果是一样的。
二、rand()使用示例
2.1、rand()与order by/group by使用随机排序分组
rand()函数用于随机生成一个不重复的数字,所以当rand()与order by组合使用时,可以实现数据随机排序。
使用场景:例如可以用于样本抽样,先对数据进行随机排序,然后抽取前x条。
注意:因为是随机排序,所以每次返回不同的结果。如果目标是以随机顺序检索行,则可以使用这样的语句。
SELECT * FROM tbl_name ORDER BY RAND();
2.2、round()与rand()的组合使用
round(n,m):对处理的数据进行四舍五入,
n:处理的数据
m:保留的小数位数
实例1.获取某个区间的数据
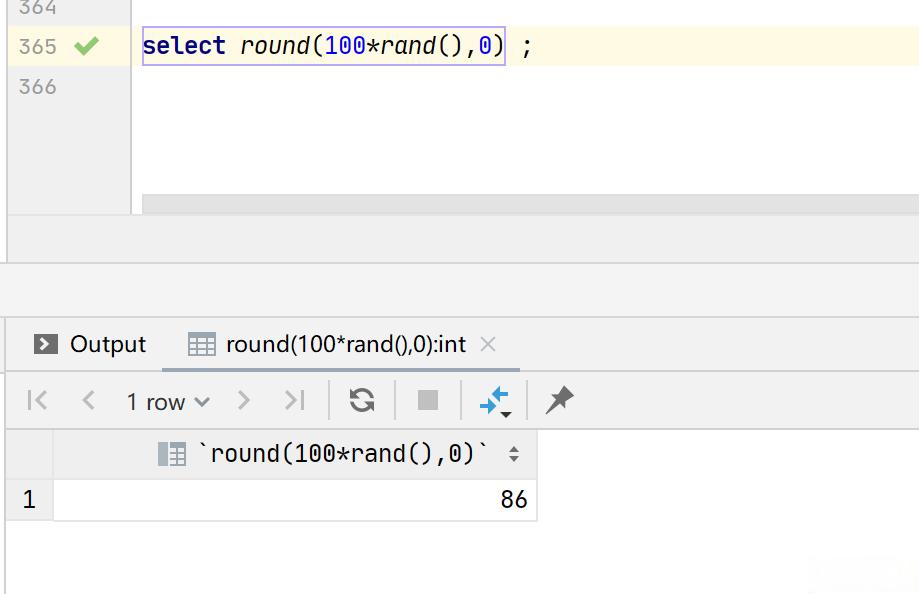
-- 获取0-100之间的整数
select round(100*rand(),0):
实例2:获取[40,60)的两位小数
select 40+round(20*rand(),2)
ps:20为60-40的差值
2.3、rand与ceiling的组合使用
ceiling(n):对于数据n向上取整
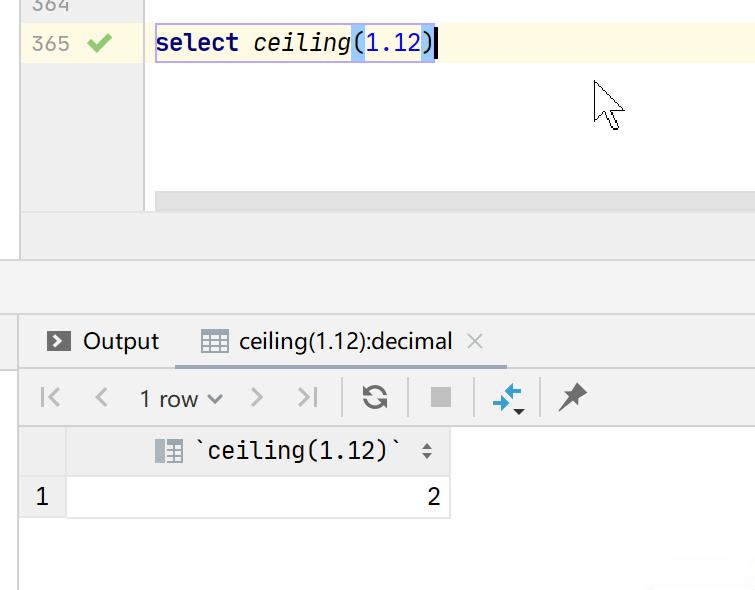
实例1:select ceiling(1.12)
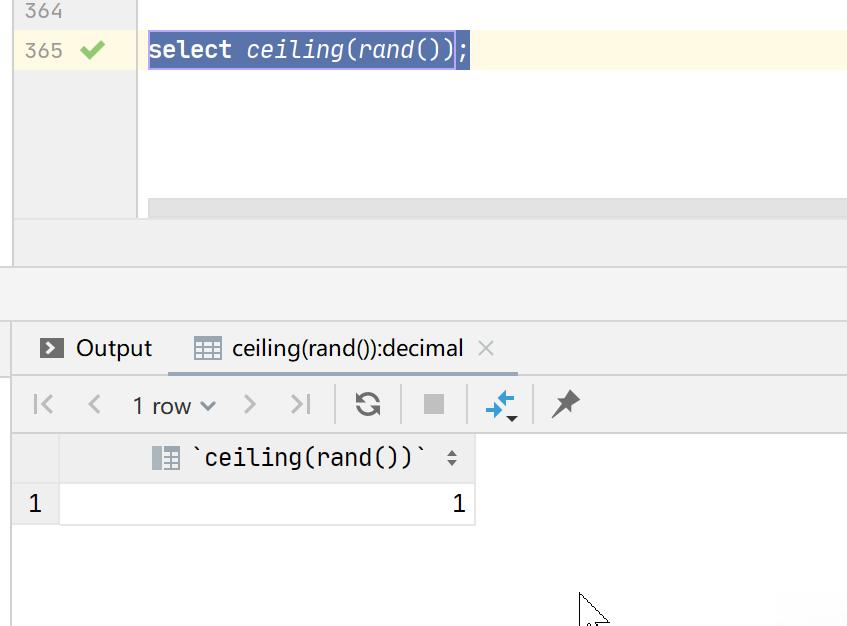
实例2:select ceiling(rand());
rand():随机在[0,1)之间,故结果肯定为1
实例3:随机获取[60,80)之间的整数
select ceiling(60+rand()*20);
2.4、rand与floor组合使用
floor():是向下取整
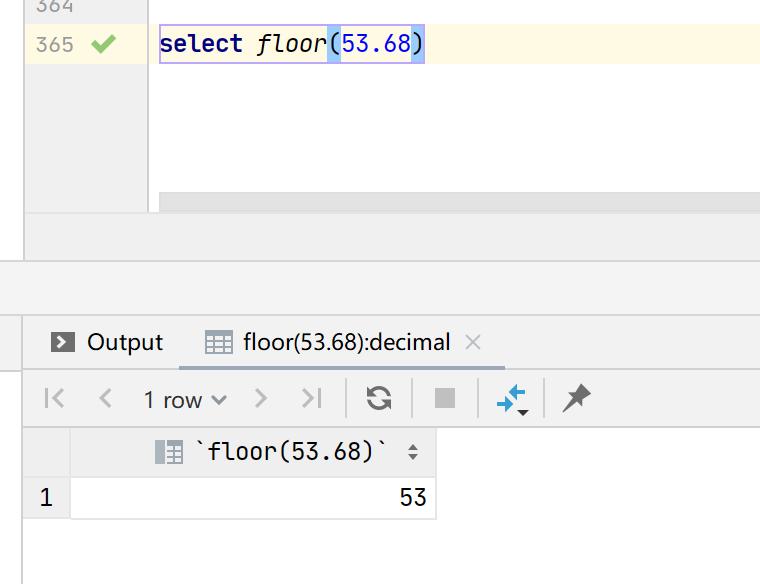
实例1:select floor(53.68)
实例2:select floor(rand());
ps:rand()向下取整必然为0
实例3:[40,52)之间取整
select floor(40+rand()*12);
2.5、rand与md5组合使用
md5(n):必须要有参数n,计算n对应的md5摘要,并返回32位的十六进制的字符串
ps:如果n为 NULL,MySQL MD5() 函数返回 NULL
实例1:select md5(123.44);
实例2:select md5(rand());
三、总结
3.1、rand()与rand(n)的区别
rand()函数
- 每次生成是随机数都是不一致且不重复的。
- 适用场景:样本抽样,对数据随机排序后获取前x条。每次排序的结果都是随机的、不一致的。
rand(n:int)函数
- n是个int类型的种子参数,每个种子生成的随机数都是不同的。但是相同的种子每次返回的随机数都是固定的。如rand(2)每次返回的值是固定的。
- 同一次查询时结果集中可能会产生重复的数字。
- 多次查询时每次返回的随机数与上一次查询结果一致。
- 适用场景:用于需要重复生成相同随机数序列的场景,例如模拟实验或测试中需要重复执行相同的随机操作。