RAG技术详解:如何提升大语言模型的准确性和可靠性
RAG技术详解:如何提升大语言模型的准确性和可靠性
随着大语言模型(LLM)的快速发展,如何提高模型的准确性和可靠性成为了一个重要课题。检索增强生成(RAG)技术通过引入外部知识库,为大语言模型提供了更强大的信息检索和生成能力。本文将详细介绍RAG的核心概念、工作流程以及与微调技术的对比分析,帮助读者全面了解这一前沿技术。
一、RAG定义
大型语言模型(LLM)相较于传统的语言模型具有更强大的能力,然而在某些情况下,它们仍可能无法提供准确的答案。为了解决大型语言模型在生成文本时面临的一系列挑战,提高模型的性能和输出质量,研究人员提出了一种新的模型架构:检索增强生成(RAG, Retrieval-Augmented Generation)。该架构巧妙地整合了从庞大知识库中检索到的相关信息,并以此为基础,指导大型语言模型生成更为精准的答案,从而显著提升了回答的准确性与深度。
检索增强生成(Retrieval Augmented Generation,RAG)通过引入外部知识,使大模型能够生成准确且符合上下文的答案,同时能够减少模型幻觉的出现。由于RAG简单有效,它已经成为主流的大模型应用方案之一。
二、解决的问题
- 信息偏差/幻觉: LLM 有时会产生与客观事实不符的信息,导致用户接收到的信息不准确。RAG 通过检索数据源,辅助模型生成过程,确保输出内容的精确性和可信度,减少信息偏差。
- 知识更新滞后性: LLM 基于静态的数据集训练,这可能导致模型的知识更新滞后,无法及时反映最新的信息动态。RAG 通过实时检索最新数据,保持内容的时效性,确保信息的持续更新和准确性。
- 内容不可追溯: LLM 生成的内容往往缺乏明确的信息来源,影响内容的可信度。RAG 将生成内容与检索到的原始资料建立链接,增强了内容的可追溯性,从而提升了用户对生成内容的信任度。
- 领域专业知识能力欠缺: LLM 在处理特定领域的专业知识时,效果可能不太理想,这可能会影响到其在相关领域的回答质量。RAG 通过检索特定领域的相关文档,为模型提供丰富的上下文信息,从而提升了在专业领域内的问题回答质量和深度。
- 推理能力限制: 面对复杂问题时,LLM 可能缺乏必要的推理能力,这影响了其对问题的理解和回答。RAG 结合检索到的信息和模型的生成能力,通过提供额外的背景知识和数据支持,增强了模型的推理和理解能力。
- 应用场景适应性受限: LLM 需在多样化的应用场景中保持高效和准确,但单一模型可能难以全面适应所有场景。RAG 使得 LLM 能够通过检索对应应用场景数据的方式,灵活适应问答系统、推荐系统等多种应用场景。
- 长文本处理能力较弱: LLM 在理解和生成长篇内容时受限于有限的上下文窗口,且必须按顺序处理内容,输入越长,速度越慢。RAG 通过检索和整合长文本信息,强化了模型对长上下文的理解和生成,有效突破了输入长度的限制,同时降低了调用成本,并提升了整体的处理效率。
三、步骤
如下图所示,RAG通常包括以下三个基本步骤:
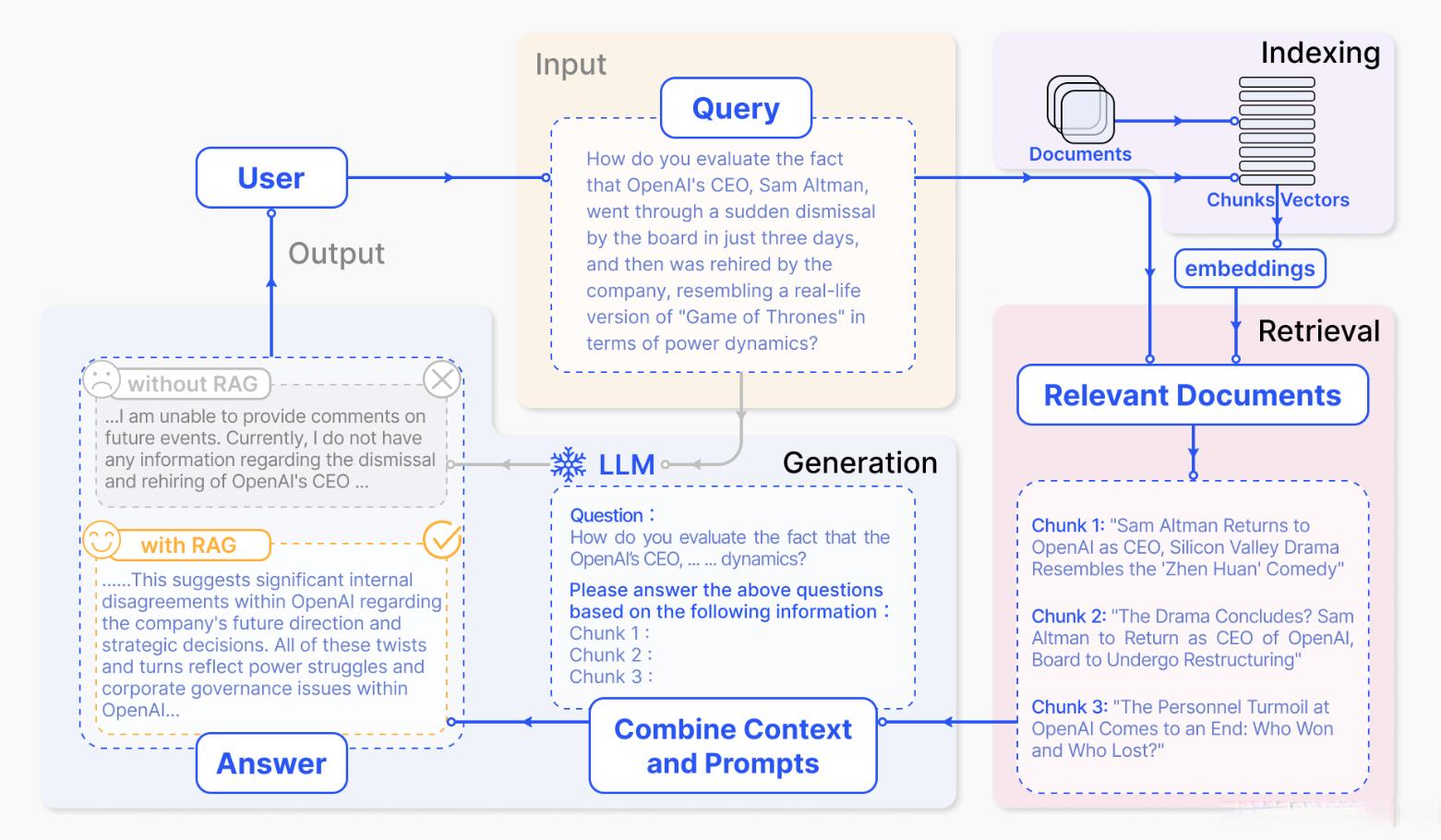
索引:将文档库分割成较短的Chunk,即文本块或文档片段,然后构建成向量索引。
检索:计算问题和 Chunks 的相似度,检索出若干个相关的 Chunk。
生成:将检索到的Chunks作为背景信息,生成问题的回答。
四、 工作流程
4.1 数据处理阶段
- 对原始数据进行清洗和处理。
- 将处理后的数据转化为检索模型可以使用的格式。
- 将处理后的数据存储在对应的数据库中。
4.2 检索阶段
- 将用户的问题输入到检索系统中,从数据库中检索相关信息。
4.3 增强阶段
- 对检索到的信息进行处理和增强,以便生成模型可以更好地理解和使用。
4.4 生成阶段
- 将增强后的信息输入到生成模型中,生成模型根据这些信息生成答案。
五、RAG链路
从下图可以看到,线上接收到用户**
query
后,RAG会先进行检索,然后将检索到的
Chunks
和
query
**一并输入到大模型,进而回答用户的问题。
为了完成检索,需要离线将文档(ppt、word、pdf等)经过解析、切割甚至OCR转写,然后进行向量化存入数据库中。
(图片来源:GitHub - netease-youdao/QAnything: Question and Answer based on Anything.)
5.1 离线计算
首先,知识库中包含了多种类型的文件,如pdf、word、ppt等,这些
文档
(Documents)需要提前被解析,然后切割成若干个较短的
Chunk
,并且进行清洗和去重。
由于知识库中知识的数量和质量决定了RAG的效果,因此这是非常关键且必不可少的环节。
然后,我们会将知识库中的所有
Chunk
都转成向量,这一步也称为
向量化
(Vectorization)或者
索引
(Indexing)。
向量化
需要事先构建一个
向量模型
(Embedding Model),它的作用就是将一段
Chunk
转成
向量
(Embedding)。如下图所示:
一个好的向量模型,会使得具有相同语义的文本的向量表示在语义空间中的距离会比较近,而语义不同的文本在语义空间中的距离会比较远。
由于知识库中的所有
Chunk
都需要进行
向量化
,这会使得计算量非常大,因此这一过程通常是离线完成的。
随着新知识的不断存储,向量的数量也会不断增加。这就需要将这些向量存储到
数据库
(DataBase)中进行管理,例如Milvus中。
5.2 在线计算
在实际使用RAG系统时,当给定一条用户
查询
(Query),需要先从知识库中找到所需的知识,这一步称为
检索
(Retrieval)。
在
检索
过程中,用户查询首先会经过向量模型得到相应的向量,然后与
数据库
中所有
Chunk
的向量计算相似度,最简单的例如
余弦相似度
,然后得到最相近的一系列
Chunk
。
由于向量相似度的计算过程需要一定的时间,尤其是
数据库
非常大的时候。
这时,可以在检索之前进行
召回
(Recall),即从
数据库
中快速获得大量大概率相关的
Chunk
,然后只有这些
Chunk
会参与计算向量相似度。这样,计算的复杂度就从整个知识库降到了非常低。
召回
步骤不要求非常高的准确性,因此通常采用简单的基于字符串的匹配算法。由于这些算法不需要任何模型,速度会非常快,常用的算法有
TF-IDF
,
BM25
等。
另外,也有很多工作致力于实现更快的
向量检索
,例如faiss,annoy。
另一方面,人们发现,随着知识库的增大,除了检索的速度变慢外,检索的效果也会出现退化,如下图中绿线所示:
(图片来源:GitHub - netease-youdao/QAnything: Question and Answer based on Anything.)
这是由于
向量模型
能力有限,而随着知识库的增大,已经超出了其容量,因此准确性就会下降。在这种情况下,相似度最高的结果可能并不是最优的。为了解决这一问题,提升RAG效果,研究者提出增加一个二阶段检索——
重排
(Rerank),即利用
重排模型
(Reranker),使得越相似的结果排名更靠前。这样就能实现准确率稳定增长,即数据越多,效果越好(如上图中紫线所示)。
通常,为了与
重排
进行区分,一阶段检索有时也被称为
精排
。而在一些更复杂的系统中,在
召回
和
精排
之间还会添加一个
粗排
步骤,这里不再展开,感兴趣的同学可以自行搜索。
综上所述,在整个
检索
过程中,计算量的顺序是
召回
精排
重排
,而检索效果的顺序则是
召回
<
精排
<
重排
。
当这一复杂的
检索
过程完成后,我们就会得到排好序的一系列
检索文档
(Retrieval Documents)。然后我们会从其中挑选最相似的
k
个结果,将它们和用户查询拼接成prompt的形式,输入到大模型。 最后,大型模型就能够依据所提供的知识来生成回复,从而更有效地解答用户的问题。
至此,一个完整的RAG链路就构建完毕了。
六、开发框架
6.1 LangChain
6.1.1 简介
该框架利用 OpenAI 提供的 API 或者私有化模型,来开发基于大型语言模型的应用程序。旨在帮助开发者们快速构建基于大型语言模型的端到端应用程序或工作流程。
LangChain 框架是一个开源工具,充分利用了大型语言模型的强大能力,以便开发各种下游应用。它的目标是为各种大型语言模型应用提供通用接口,从而简化应用程序的开发流程。具体来说,LangChain 框架可以实现数据感知和环境互动,也就是说,它能够让语言模型与其他数据来源连接,并且允许语言模型与其所处的环境进行互动。
6.1.2 核心部件
LangChian 作为一个大语言模型开发框架,可以将 LLM 模型(对话模型、embedding 模型等)、向量数据库、交互层 Prompt、外部知识、外部代理工具整合到一起,进而可以自由构建 LLM 应用。 LangChain 主要由以下 6 个核心组件组成:
- 模型输入/输出(Model I/O):与语言模型交互的接口
- 数据连接(Data connection):与特定应用程序的数据进行交互的接口
- 链(Chains):将组件组合实现端到端应用。
- 记忆(Memory):用于链的多次运行之间持久化应用程序状态;
- 代理(Agents):扩展模型的推理能力。用于复杂的应用的调用序列;
- 回调(Callbacks):扩展模型的推理能力。用于复杂的应用的调用序列;
6.2 LlamaIndex
一个用于构建大语言模型应用程序的数据框架,包括数据摄取、数据索引和查询引擎等功能。
6.3 QAnything
网易有道开发的本地知识库问答系统,支持任意格式文件或数据库。
6.4 RAGFlow
InfiniFlow开发的基于深度文档理解的RAG引擎。
七、RAG与微调对比
微调: 通过在特定数据集上进一步训练大语言模型,来提升模型在特定任务上的表现。
特征比较 RAG 微调
知识更新 直接更新检索知识库,无需重新训练。信息更新成本低,适合动态变化的数据。 通常需要重新训练来保持知识和数据的更新。更新成本高,适合静态数据。
外部知识 擅长利用外部资源,特别适合处理文档或其他结构化/非结构化数据库。 将外部知识学习到 LLM 内部。
数据处理 对数据的处理和操作要求极低。 依赖于构建高质量的数据集,有限的数据集可能无法显著提高性能。
模型定制 侧重于信息检索和融合外部知识,但可能无法充分定制模型行为或写作风格。 可以根据特定风格或术语调整 LLM 行为、写作风格或特定领域知识。
可解释性 可以追溯到具体的数据来源,有较好的可解释性和可追踪性。 黑盒子,可解释性相对较低。
计算资源 需要额外的资源来支持检索机制和数据库的维护。 依赖高质量的训练数据集和微调目标,对计算资源的要求较高。
推理延迟 增加了检索步骤的耗时 单纯 LLM 生成的耗时
降低幻觉 通过检索到的真实信息生成回答,降低了产生幻觉的概率。 模型学习特定领域的数据有助于减少幻觉,但面对未见过的输入时仍可能出现幻觉。
伦理隐私 检索和使用外部数据可能引发伦理和隐私方面的问题。 训练数据中的敏感信息需要妥善处理,以防泄露。
注:学习资料链接动手学大模型应用开发,部分内容来自Datawhle官方教程重新整理,完整教程链接Datawhale 24夏令营第四期 大模型应用开发 RAG开发-CSDN博客,后续还会根据其他资料进行完善