布隆过滤器原理与应用:如何解决缓存穿透问题
布隆过滤器原理与应用:如何解决缓存穿透问题
布隆过滤器(Bloom Filter)是一种空间效率极高的概率型数据结构,主要用于判断一个元素是否在一个集合中。虽然它允许一定的误识别率,但在处理大规模数据时,其空间效率和查询速度远超传统数据结构。本文将详细介绍布隆过滤器的基本原理、如何使用布隆过滤器解决缓存穿透问题,以及布隆过滤器的具体实现方法。
什么是缓存,缓存有什么作用
缓存通常用于存储经常访问的数据,以便快速检索,减少对原始数据源的直接访问需求。通过存储频繁访问的数据,缓存可以减少对后端数据库或服务的请求,从而减轻它们的负载。
什么是缓存穿透问题
如果查询一个不存在的数据,数据库查询不到数据也不会直接写入缓存,就会导致每次请求都查数据库,相当于缓存失效,如果这种请求很多,尤其是恶意攻击时,会对数据库造成很大的压力,甚至可能导致数据库服务不可用。
布隆过滤器解决缓存穿透问题
什么是布隆过滤器
布隆过滤器(Bloom Filter)是1970年由布隆提出的。它实际上是一个很长的二进制向量和一系列随机映射函数。布隆过滤器可以用于检索一个元素是否在一个集合中。它的优点是空间效率和查询时间都比一般的算法要好的多,缺点是有一定的误识别率和删除困难。
布隆过滤器解决缓存穿透的思路
在系统启动或定期更新时,将数据库中已经存在的所有键,这样,布隆过滤器就包含了所有合法的键。请求到达缓存前先在布隆过滤器预检查,如果布隆过滤器判断该键可能不存在,则直接返回请求不存在的结果,不再进行后续的缓存和数据库查询。如果布隆过滤器判断该键可能存在,则继续进行后续操作。
使用布隆过滤器(Redisson内集成了Bloom Filter)
引入依赖
Redisson内集成了布隆过滤器,我们可以直接使用Redisson。
<!--redisson-->
<dependency>
<groupId>org.redisson</groupId>
<artifactId>redisson</artifactId>
<version>3.13.6</version>
</dependency>
配置Redisson客户端
配置Redisson客户端,连接到Redis服务器。
import org.redisson.Redisson;
import org.redisson.api.RedissonClient;
import org.redisson.config.Config;
public class RedissonConfig {
public static RedissonClient getClient() {
Config config = new Config();
config.useSingleServer().setAddress("redis://127.0.0.1:6379");
return Redisson.create(config);
}
}
创建布隆过滤器,配置过滤器属性
使用Redisson创建一个布隆过滤器,并初始化其容量和误判率。
public class BloomFilterExample {
@Autowired
private RedissonClient redissonClient;
public static RBloomFilter<String> createBloomFilter() {
RBloomFilter<String> bloomFilter = redissonClient.getBloomFilter("bloomFilter");
// 初始化布隆过滤器,假设预期插入1000000个元素,允许的最大误判率为0.03%
bloomFilter.tryInit(1000000, 0.0003);
return bloomFilter;
}
}
使用布隆过滤器
在查询缓存之前,先使用布隆过滤器检查数据是否存在。如果布隆过滤器返回不存在,则直接返回默认值或错误信息,避免查询数据库。
import org.redisson.api.RBloomFilter;
import org.redisson.api.RedissonClient;
public class CacheService {
private final RedissonClient redissonClient;
private final RBloomFilter<String> bloomFilter;
@Autowired
public CacheService(RedissonClient redissonClient, BloomFilterExample bloomFilterExample) {
this.redissonClient = redissonClient;
this.bloomFilter = bloomFilterExample.createBloomFilter();
}
public Object getData(String key) {
// 先检查布隆过滤器
if (!bloomFilter.contains(key)) {
// 如果布隆过滤器中不存在,直接返回默认值或错误信息
return "数据不存在";
}
// 从缓存中获取数据
Object data = getFromCache(key);
if (data != null) {
return data;
}
// 如果缓存中没有数据,从数据库中查询
data = getFromDatabase(key);
if (data != null) {
// 将数据放入缓存
putToCache(key, data);
// 将数据加入布隆过滤器
bloomFilter.add(key);
} else {
// 如果数据库中也没有数据,将key加入布隆过滤器
bloomFilter.add(key);
}
return data;
}
private Object getFromCache(String key) {
// 实现从缓存中获取数据的逻辑
return redissonClient.getBucket(key).get();
}
private Object getFromDatabase(String key) {
// 实现从数据库中获取数据的逻辑
// 这里只是一个示例,实际应用中需要根据具体情况进行实现
return null;
}
private void putToCache(String key, Object value) {
// 实现将数据放入缓存的逻辑
redissonClient.getBucket(key).set(value);
}
}
布隆过滤器原理深入解读
布隆过滤器的数据结构
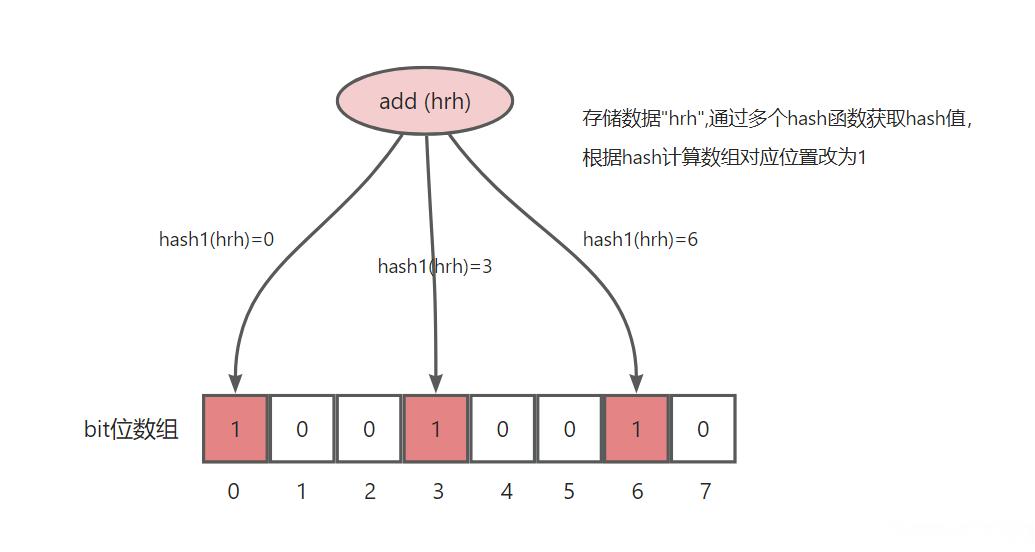
布隆过滤器(Bloom Filter)的数据结构主要由一个固定长度的位数组(Bit Array)和一组哈希函数(Hash Functions)组成。
存储数据:要存储的数据,通过多个hash函数获取hash值,根据hash计算数组对应位置改为1 。
查询数据:使用相同hash函数获取hash值,判断对应位置是否都为1。
手搓布隆过滤器
直接上代码。
import java.util.BitSet;
public class BloomFilter<T> {
// 位数组
private BitSet bitSet;
// 位数组的大小
private int size;
// 哈希函数的数量
private int hashFunctionsCount;
/**
* 构造函数,初始化布隆过滤器
* @param size 位数组的大小
* @param hashFunctionsCount 哈希函数的数量
*/
public BloomFilter(int size, int hashFunctionsCount) {
this.size = size;
this.hashFunctionsCount = hashFunctionsCount;
// 初始化位数组
this.bitSet = new BitSet(size);
}
/**
* 向布隆过滤器中添加一个元素
* @param object 要添加的元素
*/
public void add(T object) {
// 遍历每个哈希函数
for (int i = 0; i < hashFunctionsCount; i++) {
// 计算当前哈希函数的哈希值
int hash = hash(object, i);
// 将哈希值对应的位设置为 true
bitSet.set(hash % size, true);
}
}
/**
* 检查一个元素是否可能存在于布隆过滤器中
* @param object 要检查的元素
* @return 如果所有哈希值对应的位都是 true,则返回 true;否则返回 false
*/
public boolean mightContain(T object) {
// 遍历每个哈希函数
for (int i = 0; i < hashFunctionsCount; i++) {
// 计算当前哈希函数的哈希值
int hash = hash(object, i);
// 检查哈希值对应的位是否为 true
if (!bitSet.get(hash % size)) {
// 如果有任何一个位为 false,则该元素肯定不在布隆过滤器中
return false;
}
}
// 如果所有位都为 true,则该元素可能在布隆过滤器中
return true;
}
/**
* 计算对象的哈希值
* @param object 要计算哈希值的对象
* @param seed 哈希函数的种子值
* @return 计算得到的哈希值
*/
private int hash(T object, int seed) {
// 获取对象的哈希码
int hash = object.hashCode();
// 通过位运算生成不同的哈希值
hash ^= (hash >>> 20) ^ (hash >>> 12);
// 再次通过位运算和种子值生成最终的哈希值
return hash ^ (hash >>> 7) ^ (hash >>> 4) ^ seed;
}
public static void main(String[] args) {
// 创建一个布隆过滤器实例,位数组大小为 1000000,哈希函数数量为 7
BloomFilter<String> bloomFilter = new BloomFilter<>(1000000, 7);
// 添加一些元素
bloomFilter.add("apple");
bloomFilter.add("banana");
bloomFilter.add("cherry");
// 检查这些元素是否存在
System.out.println("apple: " + bloomFilter.mightContain("apple")); // 应该输出 true
System.out.println("banana: " + bloomFilter.mightContain("banana")); // 应该输出 true
System.out.println("orange: " + bloomFilter.mightContain("orange")); // 应该输出 false
}
}
布隆过滤器的优缺点总结
优点
空间效率:布隆过滤器使用位数组存储数据,因此非常节省空间,特别是对于大规模数据集。
时间效率:布隆过滤器的添加和查询操作时间复杂度接近O(1),即常数时间复杂度,非常快速。
简单性:布隆过滤器的实现相对简单,易于理解和实现。
无误漏:布隆过滤器不会错误地报告元素不存在(误漏),即如果一个元素被添加到了布隆过滤器中,那么查询时一定能被检测到。
缺点
误判:布隆过滤器允许误判(false positives),即可能会错误地报告一个元素存在。
不支持删除:标准的布隆过滤器不支持删除操作,因为删除一个元素可能会影响其他元素的测试结果。
固定大小:布隆过滤器一旦创建,其大小和哈希函数数量就固定了,这限制了其灵活性。
内存消耗:虽然布隆过滤器节省空间,但在处理非常大的数据集时,即使是优化过的布隆过滤器也可能消耗大量内存。