细说机器学习数学优化之最大似然估计
细说机器学习数学优化之最大似然估计
最大似然估计(Maximum Likelihood Estimation,MLE)是一种在统计学中用于估计模型参数的方法。这种方法基于这样一个原则:在给定的观测数据下,选择使得观测数据出现概率最大的参数值作为参数的估计值。本文将从基本原理、核心公式、步骤、性质到应用,层层递进,帮助读者深入理解最大似然估计这一重要概念。
一、基本原理
假设我们有一个统计模型,其参数为θ,并且我们有一组观测数据X。最大似然估计的目标是找到一个参数值θ_hat,使得在θ=θ_hat的条件下,观测数据X出现的概率(或概率密度)最大。这个概率(或概率密度)通常表示为L(θ; X),称为似然函数。
二、核心公式
似然函数
对数似然函数(为了简化计算):
最大化对数似然函数:
公式推导:
定义似然函数:
为了简化计算,取对数:
求导数并设导数为0,得到极值点:
解方程得到参数估计值
三、步骤
定义似然函数:根据观测数据X和模型参数θ,定义似然函数L(θ; X)。对于离散数据,这通常是概率质量函数的乘积;对于连续数据,这通常是概率密度函数的乘积。
求对数似然函数:由于似然函数往往是多个概率的乘积,直接最大化这个乘积可能比较复杂。因此,通常取对数似然函数l(θ; X) = log L(θ; X),将对数的乘法转化为加法,从而简化计算。
最大化对数似然函数:通过对对数似然函数求导,找到使其最大的参数值θ_hat。这通常涉及到解一个或多个方程,或者使用数值优化方法。
得出参数估计值:将求得的θ_hat作为模型参数的估计值。
四、性质
一致性:在样本量趋于无穷大时,最大似然估计通常是一致的,即估计值会收敛到真实参数值。
渐近正态性:在适当的条件下,最大似然估计具有渐近正态性,即当样本量足够大时,估计值的分布近似为正态分布。
有效性:在所有无偏估计量中,最大似然估计通常具有最小的方差,即它是最有效的。
五、应用
最大似然估计广泛应用于各种统计模型和数据分析中,包括但不限于线性回归、逻辑回归、广义线性模型、混合效应模型等。此外,在机器学习领域,尤其是在参数估计和模型训练中,最大似然估计也是一个重要的工具。
六、代码实战
import numpy as np
import matplotlib.pyplot as plt
from scipy.stats import norm
from scipy.optimize import minimize
# 生成模拟数据
np.random.seed(42)
true_mu = 5
true_sigma = 2
data = np.random.normal(true_mu,true_sigma,size=1000)
# 定义负对数似然函数
def neg_log_likelihood(params,data):
mu,sigma = params[0],params[1]
if sigma <= 0:
return np.inf
log_likelihood=np.sum(np.log(norm.pdf(data,mu,sigma)))
return -log_likelihood
# 使用优化器找到 MLE 参数
initial_guess = [0,1]
result = minimize(neg_log_likelihood, initial_guess, args=(data,), method='L-BFGS-B', bounds=[(None,None),(1e-5,None)])
mle_mu,mle_sigma = result.x
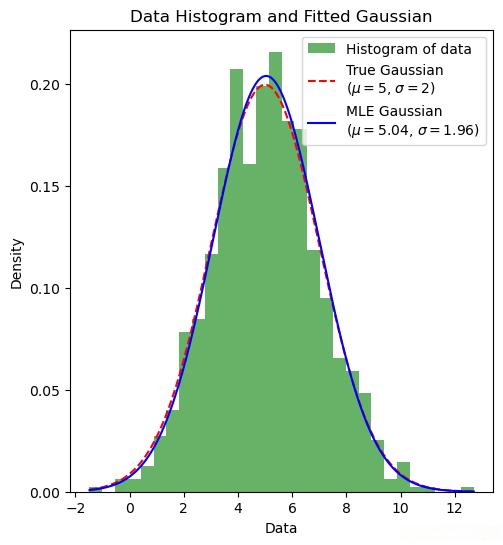
# 绘制数据的直方图与拟合的正态分布曲线对比图
x = np.linspace(min(data), max(data), 1000)
pdf_true = norm.pdf(x,true_mu,true_sigma)
pdf_mle = norm.pdf(x, mle_mu, mle_sigma)
plt.figure(figsize=(12,6))
plt.subplot(1,2,1)
plt.hist(data,bins=30,density=True,alpha=0.6,color='g',label='Histogram of data')
plt.plot(x,pdf_true,'r--',label=f'True Gaussian\n($\mu={true_mu}$, $\sigma={true_sigma}$)')
plt.plot(x,pdf_mle,'b-',label=f'MLE Gaussian\n($\mu={mle_mu:.2f}$, $\sigma={mle_sigma:.2f}$)')
plt.title('Data Histogram and Fitted Gaussian')
plt.xlabel('Data')
plt.ylabel('Density')
plt.legend()
# 绘制对数似然函数关于均值和标准差的等高线图
mu_values = np.linspace(4, 6, 100)
sigma_values = np.linspace(1.5, 2.5, 100)
log_likelihood_values = np.zeros((len(mu_values), len(sigma_values)))
for i, mu in enumerate(mu_values):
for j, sigma in enumerate(sigma_values):
log_likelihood_values[i, j] = -neg_log_likelihood([mu,sigma],data)
mu_grid, sigma_grid = np.meshgrid(mu_values, sigma_values)
plt.subplot(1, 2, 2)
contour = plt.contour(mu_grid, sigma_grid, log_likelihood_values.T, levels=50, cmap='viridis')
plt.plot(mle_mu, mle_sigma, 'ro', label='MLE Estimate')
plt.colorbar(contour, label='Negative Log-Likelihood')
plt.title('Log-Likelihood Contours')
plt.xlabel('Mean (mu)')
plt.ylabel('Standard Deviation (sigma)')
plt.legend()
plt.tight_layout()
plt.show()
效果如下:
总结
需要注意的是,虽然最大似然估计在许多情况下都非常有效,但它也有一些局限性。例如,当模型假设不正确或数据存在异常值时,最大似然估计可能会受到较大影响。此外,对于某些复杂的模型或数据分布,最大似然估计的计算可能非常困难或耗时。在这些情况下,可能需要考虑其他估计方法,如贝叶斯估计等。