Kafka,Mq,Redis作为消息队列使用时的差异?|消息队列
Kafka,Mq,Redis作为消息队列使用时的差异?|消息队列
在分布式系统中,消息队列(Message Queue,MQ)扮演着至关重要的角色,负责解耦系统、削峰填谷、提升系统的吞吐量。Kafka、传统的MQ(如RabbitMQ、ActiveMQ)和Redis在实际应用中都被广泛用作消息队列,但它们的架构设计、适用场景、性能特点却各不相同。例如,Kafka以高吞吐量著称,RabbitMQ擅长复杂的消息路由,而Redis则凭借内存存储的特性提供极低延迟的消息传输。很多开发者在选择时会感到困惑:究竟哪种消息队列最适合我的业务场景?
Kafka、MQ、Redis概述
Kafka、传统消息队列(RabbitMQ、ActiveMQ等)、Redis作为消息队列使用时,具有不同的技术架构和应用场景。
1.1 Kafka
Kafka是一个分布式的、基于日志存储的高吞吐量消息队列,适用于大数据处理、日志收集、流式计算等场景。其核心特点包括:
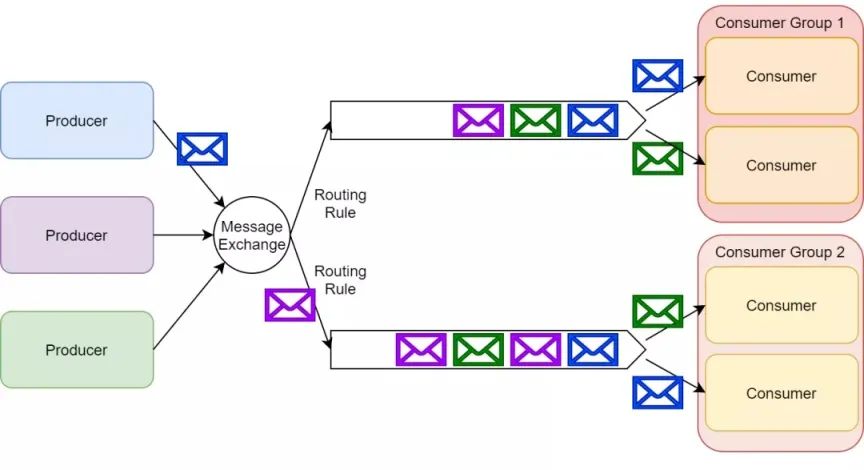
- 高吞吐量:Kafka 采用分布式架构,支持水平扩展,能够处理大规模数据流。
- 持久化存储:所有消息存储在磁盘上,默认支持数据持久化。
- 发布-订阅模式:支持多个消费者并行消费,提高处理能力。
1.2 传统消息队列(RabbitMQ、ActiveMQ)
RabbitMQ 和 ActiveMQ 采用基于 AMQP(高级消息队列协议)的架构,主要用于企业级应用,支持丰富的消息路由和事务处理。
- 低延迟:相比 Kafka,RabbitMQ 等更适合低延迟场景。
- 丰富的消息模式:支持点对点、发布-订阅、路由等多种模式。
- 事务支持:提供消息确认和事务处理能力。
1.3 Redis 作为消息队列
Redis 作为内存数据库,虽然本质上不是专门的消息队列,但可以通过 LIST、PUB/SUB 和 STREAMS 机制实现消息队列功能。
- 超低延迟:所有数据存储在内存中,读取速度极快。
- 轻量级:适用于对高吞吐低延迟要求高的场景,如实时推送。
- 持久化可选:默认数据存储在内存,支持 RDB/AOF 持久化。
2 消息持久化与可靠性
Kafka 和 RabbitMQ 通过持久化存储提高数据可靠性,而 Redis 默认是内存存储,容易因重启丢失数据。
2.1 Kafka 的持久化机制
Kafka 依赖磁盘存储消息,默认采用顺序写入日志文件,大大提高了吞吐量。
创建 Kafka 主题并发送消息
from kafka import KafkaProducer
producer = KafkaProducer(bootstrap_servers='localhost:9092')
producer.send('my_topic', b'Hello, Kafka!')
producer.flush()
2.2 RabbitMQ 的消息持久化
RabbitMQ 可以选择持久化队列和消息,以保证消息在服务器崩溃时不会丢失。
创建 RabbitMQ 队列并发送消息
import pika
connection = pika.BlockingConnection(pika.ConnectionParameters('localhost'))
channel = connection.channel()
channel.queue_declare(queue='task_queue', durable=True)
channel.basic_publish(
exchange='',
routing_key='task_queue',
body='Hello RabbitMQ!',
properties=pika.BasicProperties(delivery_mode=2) # 消息持久化
)
connection.close()
2.3 Redis 的数据持久化
Redis 使用 RDB 和 AOF 进行数据持久化,但 PUB/SUB 模式下消息不会存储。
使用 Redis LPUSH 和 BRPOP 实现消息队列
import redis
r = redis.StrictRedis(host='localhost', port=6379, decode_responses=True)
r.lpush('queue', 'Hello Redis!')
message = r.brpop('queue')
print(message[1])
3 吞吐量对比
Kafka 采用批量处理和顺序磁盘写入,吞吐量远高于 RabbitMQ 和 Redis。
4 消息一致性与事务支持
Kafka 通过 Exactly-Once 语义提供强一致性,RabbitMQ 通过 ACK 机制保证消息可靠传输,而 Redis 在 PUB/SUB 下无法保证消息可靠性。
Kafka 事务提交
producer = KafkaProducer(bootstrap_servers='localhost:9092', transactional_id='txn-1')
producer.init_transactions()
producer.begin_transaction()
producer.send('my_topic', b'Transaction Message')
producer.commit_transaction()
5 可扩展性
Kafka 由于采用分布式架构,支持水平扩展,而 RabbitMQ 主要依赖集群架构,扩展性较弱。
6 适用场景总结
- Kafka:适用于高吞吐量、持久化存储、大规模日志流处理场景。
- RabbitMQ:适用于低延迟、可靠传输、复杂路由的企业应用。
- Redis:适用于超低延迟、短时存储、实时推送场景。
结论
Kafka、RabbitMQ 和 Redis 在消息队列场景下各具特点。Kafka 以高吞吐和持久化见长,RabbitMQ 适用于低延迟和事务性应用,而 Redis 提供最快速的消息传递但持久化能力较弱。选择合适的消息队列需要根据业务需求权衡吞吐量、可靠性和可扩展性。