机器学习在科研领域的应用与未来趋势:机器学习第一性原理+分子动力学
创作时间:
作者:
@小白创作中心
机器学习在科研领域的应用与未来趋势:机器学习第一性原理+分子动力学
引用
CSDN
1.
https://blog.csdn.net/E_Magic_Cube/article/details/146319066
机器学习在科研领域的应用正日益广泛,特别是在生物信息学和材料科学中展现出巨大潜力。本文将探讨机器学习的基本原理、分类及其在科研领域的具体应用案例,以及未来的发展趋势。
“机器学习”这个词听起来很高大上,但其实概念很简单:让机器像人一样学习。
机器学习的核心是它的自学习能力,能通过训练从数据中发现规律,为各种科学问题提供创新解决方案。
简单来说,机器学习就是让计算机通过数据来学习,而不是直接告诉它该怎么做。就像我们人类一样,不是每件事都需要别人告诉我们怎么做,有时候我们通过观察和实践就能学会。

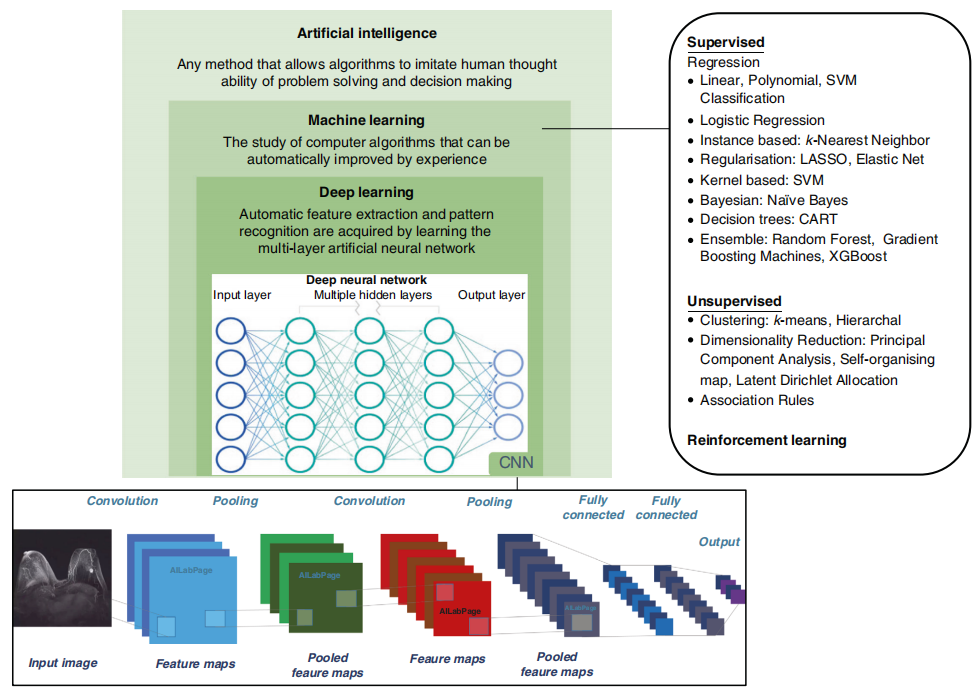
机器学习大致可以分为监督学习、无监督学习和强化学习三大类,每类方法因其特性适用于不同领域:
监督学习:通过标记好的数据训练模型,适合需要明确输入-输出关系的任务。例如,在医学领域预测疾病(如基于患者症状判断癌症风险),或在材料科学中预测材料性质(如根据化学成分预测强度)。其优势在于精度高,但需要大量标注数据。
无监督学习:从无标签数据中提取模式,适用于数据结构未知的探索性任务。例如,在市场分析中进行客户聚类,或在基因组学中识别基因表达模式。其特点是不依赖人工标注,能发现隐藏规律。
强化学习:通过试错优化策略,适合动态决策场景。例如,在机器人控制中优化路径,或在气候模拟中调整策略以适应变化环境。其核心是适应性和长期收益最大化。
这些技术为科研提供了强大的工具,尤其是在处理复杂数据和探索未知领域时。

随着机器学习在各个领域的应用不断拓展,它正迅速渗透到科研领域,尤其在生物信息学中展现出巨大潜力。随着海量生物数据的产生,传统分析方法已难以应对,而机器学习凭借其强大的数据处理能力,广泛应用于基因表达分析、疾病分类和药物筛选等任务。
例如,支持向量机、随机森林和卷积神经网络等技术,能够从复杂的生物数据中挖掘出隐藏的模式,推动疾病预测和蛋白质结构预测等领域的突破。
一篇值得关注的论文是《Nature Reviews | Molecular Cell Biology》发表的《A guide to machine learning for biologists》。这篇文章为生物学家提供了入门指南,详细介绍了机器学习的基本概念及其在生物医学中的应用。
它强调了机器学习如何帮助研究人员快速理解基因表达聚类、优化药物设计,同时也指出了实际应用中的挑战,如数据复杂性、模型可解释性和结果验证等问题。
这些挑战提醒我们,机器学习的成功依赖于高质量的数据和科学的模型设计。
案例:机器学习推断急性髓系白血病AML中的恶性细胞群
(论文标题:Single-cell dissection reveals promotive role of ENO1 in leukemia stem cell self-renewal and chemoresistance in acute myeloid leukemia)
**研究方法:**
本研究利用单细胞RNA测序技术结合机器学习算法分析了8例复发/难治性急性髓系白血病(R/R AML)患者和4名健康对照者的骨髓样本,以探究ENO1在白血病干细胞自我更新和化疗耐药性中的作用;其次,通过体外实验验证ENO1的表达水平与AML患者的临床结果之间的相关性,并测试ENO1抑制剂对AML细胞增殖的影响,以评估ENO1作为潜在治疗靶点的可行性。
机器学习在生物学领域的成功,不仅展示了其在生命科学中的价值,也启发其他学科的研究人员探索其潜力。材料科学便是其中一个迅速崛起的领域。
传统材料研究依赖实验试错,面临周期长、成本高和材料属性复杂的难题。而机器学习,尤其是深度学习等先进算法的引入,为加速材料研发和发现提供了全新的解决方案。
通过分析大规模数据,机器学习能够预测材料性质、优化设计,甚至在实验前筛选出最具潜力的候选材料。这种数据驱动的方法,正在将材料科学从依赖直觉的探索,转向更高效、智能的创新。
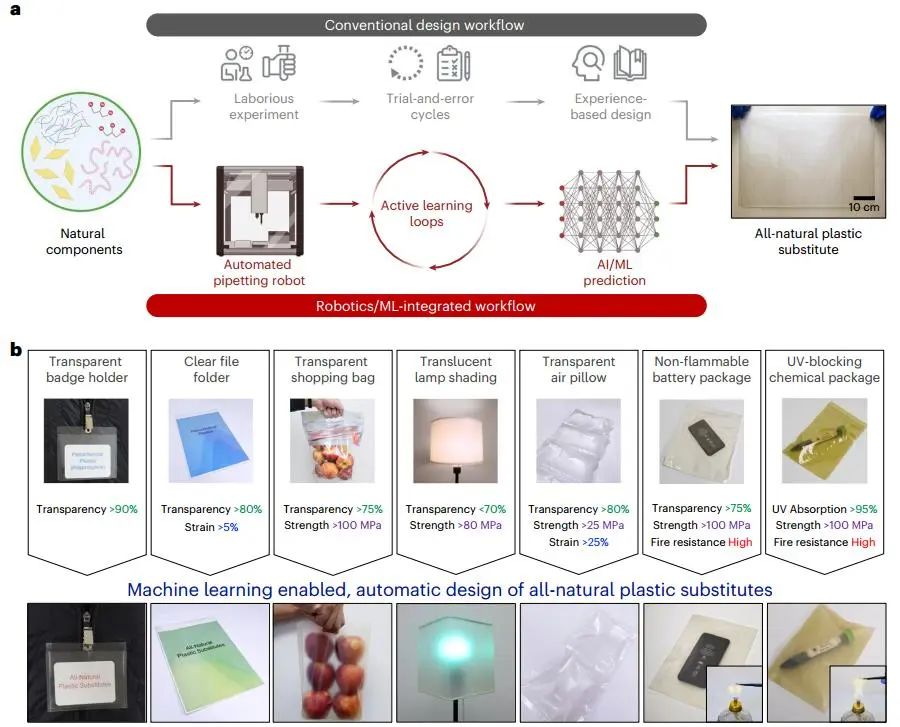
案例:机器学习助力全天然塑料替代品的发现
(论文标题:Machine intelligence-accelerated discovery of all-natural plastic substitutes)
**研究方法:**
本研究主要通过整合机器人技术和机器学习,加速发现具有可编程光学、热学和机械性能的全天然塑料替代品。利用自动化移液机器人(OT-2)制备了286个由蒙脱石(MMT)、纤维素纳米纤维(CNF)、明胶和甘油不同比例组成的纳米复合薄膜,用于初步数据收集。随后,通过14个主动学习循环,逐步制备了135个全天然纳米复合材料,结合数据增强技术,构建并优化了人工神经网络(ANN)预测模型。
*案例:机器学习预测不同镓掺杂浓度下铁电性能和铁电相的变化规律*
*(论文标题:Artificial intelligence-driven phase stability evaluation and new dopants identification of hafnium oxide-based ferroelectric materials)*
**研究方法:**
本研究主要结合了密度泛函理论(DFT)和机器学习(ML)技术,旨在探索掺杂元素对铪氧化物(HfO2)基铁电材料的影响。首先,使用DFT计算了不同掺杂浓度下铪氧化物的相稳定性,并通过Boltzmann分布理论计算铁电相的分布比例。接着,采用机器学习进行预测任务,包括支持向量机(SVM)用于分类铁电相与非铁电相,随机森林(RF)用于回归预测相能量差异和极化。通过SISSO方法优化物理特征描述符,有效提升了模型准确性。机器学习模型表现出高精度的预测能力,回归任务中的R²值分别为92.9%和95.3%。此外,使用SHAP分析解释了各特征对结果的影响,揭示了掺杂元素的离子半径和电负性对材料性能的关键作用。通过这一框架,论文不仅加速了新材料的发现,还为HfO2基铁电材料的优化提供了新的思路。
- 案例:机器学习辅助Fe基MGs/NCs开发的流程图
(论文标题:Integrating Ultra-high Saturation Magnetization Intensity and Extreme-low Coercivity in FeCoBSiCu Alloy Assisted by Machine Learning) - **研究方法:**
本研究通过机器学习技术构建了人工神经网络,以接近95%的预测精度,从486,000种可能的组成中筛选出最优的FeCoBSiCu合金。该合金不仅实现了1.96 T的超高Bs,还达到了1.2 A/m的极低Hc,打破了长久以来Bs与Hc之间的权衡关系,超越了所有先前报道的软磁材料。这一成果在理论上具有突破性,而且在实际应用中也显示出巨大的潜力,为软磁材料的组成设计提供了新的思路
这些案例充分证明,机器学习正在成为材料科学中不可或缺的工具,推动从概念验证到实际应用的快速转变。
随着机器学习在材料科学中的不断拓展,其应用已不再局限于传统研究方法,而是开始渗透到更深层次的计算工具中,例如分子动力学和第一性原理计算。
理论计算,例如第一性原理计算(基于密度泛函理论,DFT)和分子动力学(MD)模拟,是理解微观世界的重要工具。它们通过求解薛定谔方程或牛顿运动方程,揭示原子尺度下的物理和化学行为。
然而,这些方法各有局限:第一性原理计算精度高,但计算成本随体系规模呈指数增长,难以应用于大体系;
机器学习通过数据驱动的方式,可以在第一性原理计算的基础上,减少对大规模计算资源的依赖,提升计算效率和精度。
分子动力学虽可模拟较大体系,却依赖经验力场,精度有限,难以捕捉复杂的电子效应。
但通过引入机器学习力场(ML-FFs),可以加速材料的性能预测和优化,甚至可以预测某些实验前未曾测试的物理特性。 - 案例:通过机器学习分子动力学模拟揭示了Ti3O5中β相到λ相的层状转变机制。
(论文标题:Layer-by-layer phase transformation in Ti3O5 revealed by machine-learning molecular dynamics simulations) - **研究方法:**
这篇论文研究了Ti₃O₅从β相到λ相的重构相变,采用的主要研究方法包括机器学习潜力(MLP)开发、元动力学模拟和大规模分子动力学模拟。在机器学习方面,研究团队开发了一种高效的力矩张量潜力(MTP),通过在线主动学习方法训练,结合高级采样技术,从分子动力学轨迹中迭代选择代表性构型进行DFT计算,确保训练数据集(3775个96原子结构)覆盖相关相空间。MTP的准确性通过与DFT结果及实验数据的结构参数、能量-体积曲线和声子色散关系比较得到验证。利用此MLP,研究者在元动力学模拟中采用XRD峰强度和层特异性结构描述符作为集体变量,探索自由能景观,揭示了通过中间亚稳态相的层状转换路径。此外,大规模分子动力学模拟进一步确认了这一机制,显示相变始于ab平面内的二维成核,随后沿c轴层间传播。这种综合方法不仅阐明了β-λ相变的超快可逆特性,还为研究复杂结构相变提供了强大策略。 - 案例:通过机器学习第一性原理:设计高性能多主元高熵碳化物陶瓷
(论文标题:Local-distortion-informed exceptional multicomponent transition-metal carbides uncovered by machine learning ) - **研究方法:**
这篇论文的研究方法主要集中于利用机器学习技术预测和设计高性能多组分碳化物(MTMCs)。作者首先通过密度泛函理论(DFT)构建了一个包含三元至六元MTMCs的数据库,获取其机械性能和结构畸变数据。随后,他们以物理描述符(如前驱体性质)为输入特征,训练了一个人工神经网络(ANN)模型,预测MTMCs的机械性能,包括体积模量(B)、剪切模量(G)、杨氏模量(E)和维氏硬度(H_v)。在机器学习方面,作者通过交叉验证和超参数优化(如隐藏层数、神经元数量)提升模型准确性和泛化能力,最终实现3.54%的平均绝对百分比误差(MAPE)。训练好的ANN模型被用于高通量预测等原子和非等原子MTMCs的性能,发现其机械性能不遵循平均值法则(ROM)且与价电子浓度(VEC)弱相关。结合几何和电子结构分析,作者提出元素对岩盐结构的适应性(以局部畸变量化)是关键影响因素,并基于此推荐了V-Nb-Ta基MTMCs,经实验验证了预测结果。
近年来,机器学习与理论计算的结合已取得显著进展,尤其在材料科学、化学和物理学领域,涌现出许多成功的应用案例和工具。
(1)机器学习力场的崛起
DeePMD系列软件:作为生态最完善的机器学习力场工具之一,DeePMD利用深度神经网络学习原子间的相互作用,已广泛应用于固体、液体和界面体系的模拟。它能在保持第一性原理精度的同时,完成大规模分子动力学模拟。
等变模型的突破:如NequIP、MACE和Allegro等模型,通过引入旋转、平移等对称性约束,大幅提升了数据利用率和模型泛化能力。这些模型在描述复杂分子和材料电子结构时表现出色,成为当前研究的热点
(2)高通量计算的加速器
机器学习与高通量计算结合,使得材料筛选效率显著提高。例如,通过预测材料的带隙(band gap)或催化活性,研究人员能在实验前筛选出潜力候选者,缩短研发周期。
(3)开源生态的繁荣
开源工具如pymatgen、matminer为数据处理和模型训练提供了便利,而MACE-OFF23、MACE-MP0等通用大模型的出现,则为跨领域模拟提供了统一解决方案。
然而,尽管机器学习在多个领域展现了巨大潜力,但仍然面临不少挑战。
首先,数据质量与数量是目前最大的问题之一。在许多领域,尤其是材料科学和生物医药领域,数据的获取、处理和标注成本高昂,而且缺乏足够的数据来训练高效的机器学习模型。
其次,模型的可解释性仍然是机器学习应用中的一个难点。许多先进的机器学习算法,如深度神经网络,虽然能够提供高度准确的预测,但其内在机制往往无法为研究人员清晰解释。
如何提升机器学习模型的可解释性,让其预测结果更具信任性和科学性,仍是未来需要攻克的重点。
此外,现有的机器学习方法在某些复杂体系中仍然难以发挥作用。例如,在多物理场耦合的系统中,模型往往需要同时考虑多个因素的交互作用,这种高维度、多样性的系统依然是机器学习应用中的一大挑战。
不过随着计算能力的提升与算法的不断改进,机器学习与理论计算的结合有望进入一个新的发展阶段。
AI驱动的智能设计将成为研究的主流趋势,未来的科研工作不再局限于数据分析和模型推导,而是可以通过智能化系统自动生成研究方向,自动优化实验设计,甚至自动生成实验模型。
热门推荐
腊月腌咸鱼,最佳时间揭秘
别大意!半年便秘拖成肠癌,这4个症状可能是肠癌的先兆
稳定学习预后标志物,多种癌症生存曲线证实!清华最新成果登Nature顶级子刊
结直肠癌分期与精准治疗
糖尿病患者如何摆脱“糖分焦虑”
糖尿病患者居家管理:三忌三慎保健康
火星蚁进化之谜被破解!
四川盆地揭秘:三叠纪-侏罗纪之交的昆虫与植物“相爱相杀”
都二霞教授带你探秘昆虫世界
中国科学技术大学:权威榜单前三的学术实力
中国科大螺旋机器人创新突破,展现广阔应用前景
中国科学技术大学与中国移动签署战略合作协议
麦克斯韦方程组
雅思口语高分技巧:六大类连贯性用语详解
“3·15”小周爆料 | 在交易猫买卖游戏账号,为何钱号两空?
桂平到贵港两日游:西山风景名胜区深度游览攻略
黄精养生新潮流:这样吃最有效!
2024数博会:首批全国一体化算力网应用优秀案例发布
白蚁:地球的“清道夫”还是害虫?
白蚁基因组计划揭秘:从社会结构到生态应用
白蚁巢寄生的秘密:共存与智慧的生存艺术
深圳市白蚁防治服务中心教你防白蚁护农田
糖尿病患者饮酒小心心血管“爆表”
糖尿病患者饮酒指南:小心肝脏报警!
销项税普票也能抵扣?真相揭秘
磁控胶囊胃镜:无创检查精度达94%,双体位设计更人性化
胶囊内镜:无痛检查新选择,这些情况仍需传统胃肠镜
对话系统如何读懂你的心?
动态再平衡策略助力基金投资:定期调整持仓比例
10年期国债收益率降至2.06%,债市投资价值凸显