单入单出队列性能优化(Lock-Free)
单入单出队列性能优化(Lock-Free)
单入单出队列(SPSC)是高性能并发编程中的重要数据结构,其性能优化对于提升系统整体效率至关重要。本文将从基础实现到高级优化,深入探讨如何通过Lock-Free技术、数据对齐、索引缓存和位运算等手段,实现单入单出队列的性能最大化。
1. 线程安全循环队列
我们先简单描述下有锁线程安全的队列的实现。首先是循环队列的实现。
循环队列的实现比较简单。首先,申请一个固定大小的内存,也就是图示的capacity长度。然后维护两个游标in和out,in是插入的位置,out是元素出队的位置。当in==out时,表示队列为空。为了方便表示队列满,队列的最后一块内存空闲出来,也就是当(in + 1) % capacity == out时队列满。
入队时将插入值写入data[in],然后in=(in+1)%capacity即可(为了线程安全,我们操作前进行加锁)。
bool push(const value_type& v){
std::unique_lock<std::mutex> lock(_mutex);
if(full(0)){
return false;
}
alloc_traits::construct(_alloc, _data + _in, v);
_in = (_in + 1)%_cap;
return true;
}
出队时将data[out]处的元素出队并且销毁队列内存上的对象,out=(out+1)%capacity即可。
bool pop(value_type & v){
std::unique_lock<std::mutex> lock(_mutex);
if(empty(0)){
return false;
}
v = std::move(_data[_out]);
_data[_out].~value_type();
_out = (_out + 1)%_cap;
return true;
}
2. Lock-Free
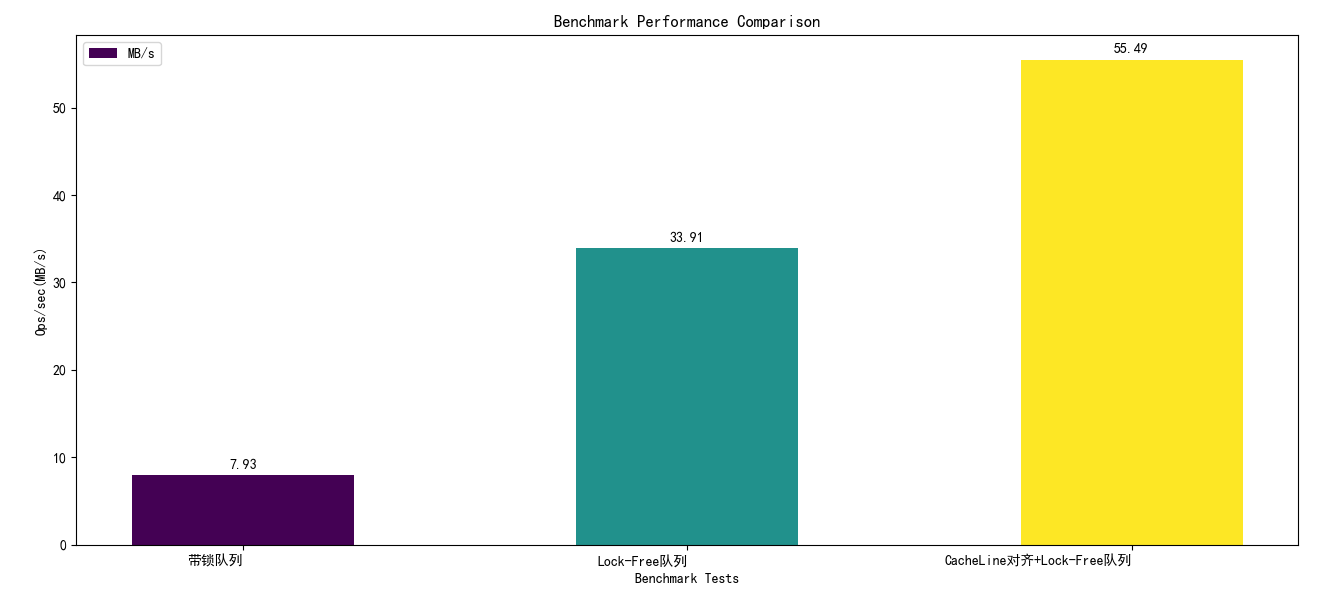
多线程访问队列存在线程安全问题,为了保证线程安全,通过加锁来保证不同线程的安全性。但是锁的粒度太大,在访问冲突比较大的场景下,在临界区多线程依然是串行的,容易造成性能问题。因此一个优化思路是使用原子变量来实现Lock-Free的线程安全队列。Lock-Free的线程安全队列能够最小化不同线程之间的数据竞争,增加并发度。
bool push(const value_type& v){
const auto inCur = _in.load(std::memory_order_relaxed);
const auto outCur = _out.load(std::memory_order_acquire);
if(full(inCur, outCur)){
return false;
}
alloc_traits::construct(_alloc, _data + inCur, v);
_in.store((inCur + 1) % capacity(), std::memory_order_release);
return true;
}
bool pop(value_type &val){
const auto inCur = _in.load(std::memory_order_acquire);
const auto outCur = _out.load(std::memory_order_relaxed);
if (empty(inCur, outCur)) // (3)
return false;
val = std::move(_data[outCur]);
alloc_traits::destroy(_alloc, _data + outCur);
_out.store((outCur + 1) % capacity(), std::memory_order_release); // (4)
return true;
}
能够看到单入单出队列使用Lock-Free之后性能优化非常明显。
3. 数据对齐
数据对齐到CPU的Cacheline能够减低伪共享的概率。CPU 通常使用缓存来加速内存访问。数据在内存中是以缓存行(通常为 64 字节)为单位进行加载的。当一个线程修改一个变量时,整个缓存行会被标记为无效,这会影响到同一缓存行中的其他变量,即使这些变量并未被修改。尽管访问的是不同的变量,但由于它们共享同一个缓存行,不同线程的并发执行可能会导致频繁的缓存失效,进而影响性能。
数据对齐的实现比较简单,下面代码中的pad是为了保证不同索引在不同的缓存行。
static constexpr auto hardware_destructive_interference_size = size_type{ 64 };
value_type* _data{};
char _pad0[hardware_destructive_interference_size]{};
alloc _alloc{};
char _pad1[hardware_destructive_interference_size]{};
alignas(hardware_destructive_interference_size) size_type _cap{};
char _pad2[hardware_destructive_interference_size]{};
alignas(hardware_destructive_interference_size) AtomicType _in{};
char _pad3[hardware_destructive_interference_size]{};
alignas(hardware_destructive_interference_size) AtomicType _out{};
4. 索引缓存
对于单入单出队列,如果push的时候如果上一次未满,这一次push也未满,pop同理,此时并不需要强行访问索引。因此可以增加索引缓存保存上一次索引的值,避免索引访问冲突而导致的CPU缓存刷新。但是需要注意的是这种方式只有索引竞争比较激烈的情况下才会有性能优化,否则可能有副作用。
bool push(const value_type& v) {
const auto inCur = _in.load(std::memory_order_relaxed);
if (full(inCur, _outCache)) {
_outCache = _out.load(std::memory_order_acquire);
if (full(inCur, _outCache)) {
return false;
}
}
alloc_traits::construct(_alloc, _data + inCur, v);
_in.store((inCur + 1) % capacity(), std::memory_order_release);
return true;
}
bool pop(value_type& val) {
const auto outCur = _out.load(std::memory_order_relaxed);
if (empty(_inCache, outCur)) {
_inCache = _in.load(std::memory_order_acquire);
if (empty(_inCache, outCur)) {
return false;
}
}
val = std::move(_data[outCur]);
alloc_traits::destroy(_alloc, _data + outCur);
_out.store((outCur + 1) % capacity(), std::memory_order_release); // (4)
return true;
}
下面的数据带锁性能非常差,是因为大幅度降低队列的长度,增加缓存的竞争,导致带锁近乎于串行访问。
5. Mask
引入Mask实际上是为了优化循环队列%的耗时。而mask是利用位运算替代除余。具体实现比较简单,只需要限制构造输入的cap一定是2^n,而实际的cap也就是下面的成员mask
为2^n-1,对应的二进制位0x111...111。这样当队列满的时候只需要cur&mask就能替代除余操作。
ThreadSafeQueueLockFreeAlignCacheMask(const size_type cap)
: _mask(cap - 1) {
_data = alloc_traits::allocate(_alloc, cap);
}
auto full(const size_type inCur, const size_type outCur) const {
return ((inCur + 1) & _mask) == outCur;
}
auto empty(const size_type inCur, const size_type outCur) const {
return inCur == outCur;
}
bool push(const value_type& v) {
const auto inCur = _in.load(std::memory_order_relaxed);
if (full(inCur, _outCache)) {
_outCache = _out.load(std::memory_order_acquire);
if (full(inCur, _outCache)) {
return false;
}
}
alloc_traits::construct(_alloc, _data + inCur, v);
_in.store((inCur + 1) & _mask, std::memory_order_release);
return true;
}
bool pop(value_type& val) {
const auto outCur = _out.load(std::memory_order_relaxed);
if (empty(_inCache, outCur)) {
_inCache = _in.load(std::memory_order_acquire);
if (empty(_inCache, outCur)) {
return false;
}
}
val = std::move(_data[outCur]);
alloc_traits::destroy(_alloc, _data + outCur);
_out.store((outCur + 1) & _mask, std::memory_order_release); // (4)
return true;
}
6. 参考文献
- Single Producer Single Consumer Lock-free FIFO From the Ground Up - Charles Frasch - CppCon 2023
- Github: Single Producer Single Consumer Lock-free FIFO From the Ground Up - Charles Frasch - CppCon 2023