R语言数据框深度解析:从创建到数据操作,一文掌握核心技能
R语言数据框深度解析:从创建到数据操作,一文掌握核心技能
数据框(data.frame)可能是大家最常用的数据结构了。数据读进来一般默认都是数据框结构。数据框由不同的行和列构成,不同的列可以是不同类型(数值型、字符型、逻辑型等)的数据,比如可以其中一列是数值型,另一列是逻辑型,另一列是字符型,等。但是同一列中必须是相同的类型。
数据框的创建
手动创建
数据框可通过函数 data.frame() 创建,使用方式如下:
#创建数据框
df <- data.frame(
Name = c("Alice", "Bob", "Charlie", "Diana", "Eve"),
Age = c(24, 22, 23, 25, 21),
Gender = c("Female", "Male", "Male", "Female", "Female"),
Score = c(85, 90, 78, 92, 88)
)
#输出
print(df)
Name、age、Gender、Score等作为列向量可为任何类型(如字符型、数值型或逻辑型)。代码会创建一个数据框,这个数据框有4列,第一列的名字是 Name,是字符型;第二列的名字是 Age,是数值型;第三列的名字是 Gender,是字符型;第4列的名字是 Score,是数值型。所以也可以把数据框看成是多个向量的组合。
数据的导入与查看
读取外部数据
df <- read.csv("test.csv") # 读取 CSV 文件
head(df) # 查看前 6 行
str(df) # 数据框结构
summary(df) # 数据统计摘要
dim(df) # 数据框的行和列数
read.csv()函数是 R 的基础函数,功能强大,但对于文件的要求较为严格,比如:文件必须是 CSV 格式(用逗号分隔的数据);文件的分隔符必须是逗号(,),否则需要用read.table()并手动指定 sep 参数。
如果需要读取不同类型的文件(例如,分隔符不是逗号的文件、.xlsx 文件或其他文本格式),可以使用tidyverse包提供的功能,例如readr和readxl。
数据访问与操作
访问数据
数据框和向量不一样,向量是一维的,数据框既有行也有列,数据框是二维的,所以在使用方括号时,我们也要指定行和列,行和列之间用 , 隔开, , 前面表示行,后面表示列。
df$Name # 获取“Name”列
df[1, 2] # 取第1行第2列的值
df[, 1:3] # 取所有行,以及第1列到第3列
df[c(1,3)] # 取所有行,以及第1列和第3列
df[1:3, ] # 获取前 3 行
df[, c("Name", "Score")] # 获取指定列
df[df$Score > 85, ] # 条件筛选
添加与删除列
df$Pass <- df$Score >= 80 # 添加“Pass”列
df$Pass <- NULL # 删除“Pass”列
数据排序
按列排序
df <- df[order(df$Score, decreasing = TRUE), ] # 按“Score”降序排列
数据分组与聚合
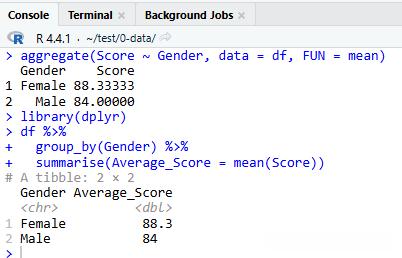
#使用 `aggregate` 聚合
aggregate(Score ~ Gender, data = df, FUN = mean) # 按“Gender”分组求均值
#使用 `dplyr` 包分组
library(dplyr)
df %>%
group_by(Gender) %>%
summarise(Average_Score = mean(Score))
缺失值处理
#### 检查缺失值
is.na(df) # 检查缺失值
sum(is.na(df)) # 缺失值总数
#### 填补缺失值
df$Score[is.na(df$Score)] <- mean(df$Score, na.rm = TRUE) # 用均值填补
#### 删除缺失值
df <- na.omit(df) # 删除包含缺失值的行
修改和重编码
df$Gender[df$Gender == "Male"] <- "男"
#把Gender这一列中的Male变成“男”
df
df$Score[df$Score >= 85] <- "优"
df$Score[df$Score < 85] <- "良"
#把Score这一列中大于等于85的变成优,小于85的变成良
df
行列转置
#行变成列,列变成行
tran_df <- t(df)
tran_df
行列拼接
拼接列:把列拼起来,也就是对多个数据框水平堆叠,也就是在一个数据框的右侧添加另一个数据框,要求行数相同。
拼接行:把行拼起来,也就是对多个数据框垂直堆叠,也就是在一个数据框的下方添加另一个数据框,要求列数相同。
# 创建两个数据框
df1 <- data.frame(
ID = c(1, 2, 3),
Name = c("Alice", "Bob", "Charlie")
)
df2 <- data.frame(
Age = c(24, 25, 23),
Gender = c("Female", "Male", "Male")
)
# 水平拼接(按列拼接)
df_combined <- cbind(df1, df2)
# 查看结果
print(df_combined)
# ID Name Age Gender
#1 1 Alice 24 Female
#2 2 Bob 25 Male
#3 3 Charlie 23 Male
# 创建两个数据框
df3 <- data.frame(
ID = c(1, 2, 3),
Name = c("Alice", "Bob", "Charlie")
)
df4 <- data.frame(
ID = c(4, 5),
Name = c("Diana", "Eve")
)
# 垂直拼接(按行拼接)
df_combined <- rbind(df3, df4)
# 查看结果
print(df_combined)
# ID Name
#1 1 Alice
#2 2 Bob
#3 3 Charlie
#4 4 Diana
#5 5 Eve
数据框合并
具有共同信息的两个数据框可以合并到一个数据框中。假设有两个数据框 df5 和 df6,它们通过公共列 ID 进行合并。
# 创建两个数据框
df5 <- data.frame(
ID = c(1, 2, 3),
Name = c("Alice", "Bob", "Charlie")
)
df6 <- data.frame(
ID = c(1, 2, 4),
Score = c(85, 90, 78)
)
# 基于公共列 ID 进行合并
df_merged <- merge(df5, df6, by = "ID")
# 查看结果
print(df_merged)
其他合并方式
保留所有行(外连接):
df_merged <- merge(df5, df6, by = "ID", all = TRUE)
保留左侧数据框的所有行(左连接):
df_merged <- merge(df5, df6, by = "ID", all.x = TRUE)
保留右侧数据框的所有行(右连接):
df_merged <- merge(df5, df6, by = "ID", all.y = TRUE)
下期内容
下一节我们学习R语言其他的数据结构